/*
@Kun Duan
Simple LED sensing
Two LED required:
ledPin connects the output LED
analogPin connects the input LED as a light sensor
Note that the input LED MUST have its +/- legs inversed
*/
int ledPin = 13; // LED '13 pin as output
int analogPin = 0;
int value = LOW;
int val = 0;
long previousMillis = 0;
long interval = 120;
void setup()
{
pinMode(ledPin, OUTPUT); // set pin mode as OUTPUT
Serial.begin(9600); // set baud rate as 9600 bps
}
void loop()
{
if (millis() - previousMillis > interval) // run program every "interval" msec
{
previousMillis = millis();
val = analogRead(analogPin); // read analog input
if(val < 10) // set output led value as HIGH
value = HIGH;
else
{
value = LOW;
}
digitalWrite(ledPin, value); // write value to led pin
Serial.print("DETECT:"); // send back analog input through serial port Serial.println(val);
}
}
%%%%%%%%%%%%%%%%%%%%%
Below is a demo video
%%%%%%%%%%%%%%%%%%%%%
Tuesday, December 28, 2010
Friday, November 26, 2010
FIFA Announces 55-Man Shortlist For 2010 World XI
Fifty-five players shortlisted for FIFA/FIFPro World XI 2010
(FIFA.com) Thursday 25 November 2010
Getty ImagesThe worldwide players’ union FIFPro and FIFA today announced
the 55 players shortlisted for the FIFA/FIPro World XI 2010 (see full list
below), which is to be revealed at the FIFA Ballon d’Or gala in Zurich on
10 January 2011.
The 50,000 professional footballers belonging to the players’ unions across
the world that form FIFPro received voting forms in a secret ballot to
nominate their peers for inclusion in their World XI – choosing the best
four defenders, three midfielders, three forwards and goalkeeper of 2010.
World champions Spain lead the way with the most players in the shortlist
with ten, followed by nine from Brazil, eight from Argentina, six from
England, four from Germany, three each from the Netherlands and Italy, two
from Portugal and one each from Uruguay, Wales, France, Bulgaria, Serbia,
the Czech Republic, Sweden, Ghana, the Ivory Coast and Cameroon.
Spain’s Primera Division attracted the most nominees with 18, followed by
England’s Premier League with 17 and Italy’s Serie A with 15. Four
nominees came from Germany’s Bundesliga and one from France’s Ligue 1.
The final FIFA/FIFPro World XI will be announced at the FIFA Ballon d’Or
gala in the Zurich Kongresshaus on 10 January 2011. During this televised
gala, the winner of the FIFA Ballon d’Or for the best player of 2010 and
the FIFA Women’s World Player of the Year 2010 award will also be revealed.
Meanwhile, the FIFA World Coach of the Year for Men’s Football award and
the FIFA World Coach of the Year for Women’s Football award will be
presented for the first time, while the FIFA Puskas Award for the best goal
of the year will be announced for the second year running. The FIFA
Presidential Award and the FIFA Fair Play Award will also be presented
during the gala.
The 55-player shortlist in full:
Goalkeepers: Gianluigi Buffon (Italy, Juventus FC), Iker Casillas (Spain,
Real Madrid C.F.), Petr Cech (Czech Republic, Chelsea FC), Julio Cesar
(Brazil, F.C. Internazionale), Edwin van der Sar (Netherlands, Manchester
United FC)
Defenders: Daniel Alves (Brazil, FC Barcelona), Gareth Bale (Wales,
Tottenham Hotspur), Michel Bastos (Brazil, Olympique Lyonnais), Ashley Cole
(England, Chelsea FC), Patrice Evra (France, Manchester United FC), Rio
Ferdinand (England, Manchester United FC), Philipp Lahm (Germany, FC Bayern
Munchen), Lucio (Brazil, F.C. Internazionale), Maicon (Brazil, F.C.
Internazionale), Marcelo (Brazil, Real Madrid C.F.), Alessandro Nesta
(Italy, AC Milan), Pepe (Portugal, Real Madrid C.F.), Gerard Pique (Spain,
FC Barcelona), Carles Puyol (Spain, FC Barcelona), Sergio Ramos (Spain, Real
Madrid C.F.), Walter Samuel (Argentina, F.C. Internazionale), John Terry
(England, Chelsea FC), Thiago Silva (Brazil, AC Milan), Nemanja Vidic
(Serbia, Manchester United FC), Javier Zanetti (Argentina, F.C.
Internazionale)
Midfielders: Esteban Cambiasso (Argentina, F.C. Internazionale), Michael
Essien (Ghana, Chelsea FC), Cesc Fabregas (Spain, Arsenal FC), Steven
Gerrard (England, Liverpool FC), Andres Iniesta (Spain, FC Barcelona),
Ricardo Kaka (Brazil, Real Madrid C.F.), Frank Lampard (England, Chelsea
FC), Javier Mascherano (Argentina, FC Barcelona), Thomas Muller (Germany, FC
Bayern Munchen), Mesut Ozil (Germany, Real Madrid C.F.), Andrea Pirlo
(Italy, AC Milan), Bastian Schweinsteiger (Germany, FC Bayern Munchen),
Wesley Sneijder (Netherlands, F.C. Internazionale), Xabi Alonso (Spain, Real
Madrid C.F.), Xavi (Spain, FC Barcelona)
Forwards: Dimitar Berbatov (Bulgaria, Manchester United FC), Didier Drogba
(Ivory Coast, Chelsea FC), Samuel Eto’o (Cameroon, F.C. Internazionale),
Diego Forlán (Uruguay, Atletico Madrid), Gonzalo Higuain (Argentina, Real
Madrid C.F.), Zlatan Ibrahimovic (Sweden, AC Milan), Lionel Messi
(Argentina, FC Barcelona), Diego Milito (Argentina, F.C. Internazionale),
Arjen Robben (Netherlands, FC Bayern München), Ronaldinho (Brazil, AC
Milan), Cristiano Ronaldo (Portugal, Real Madrid C.F.), Wayne Rooney
(England, Manchester United FC), Carlos Tevez (Argentina, Manchester City
FC), Fernando Torres (Spain, Liverpool FC), David Villa (Spain, FC Barcelona)
(FIFA.com) Thursday 25 November 2010
Getty ImagesThe worldwide players’ union FIFPro and FIFA today announced
the 55 players shortlisted for the FIFA/FIPro World XI 2010 (see full list
below), which is to be revealed at the FIFA Ballon d’Or gala in Zurich on
10 January 2011.
The 50,000 professional footballers belonging to the players’ unions across
the world that form FIFPro received voting forms in a secret ballot to
nominate their peers for inclusion in their World XI – choosing the best
four defenders, three midfielders, three forwards and goalkeeper of 2010.
World champions Spain lead the way with the most players in the shortlist
with ten, followed by nine from Brazil, eight from Argentina, six from
England, four from Germany, three each from the Netherlands and Italy, two
from Portugal and one each from Uruguay, Wales, France, Bulgaria, Serbia,
the Czech Republic, Sweden, Ghana, the Ivory Coast and Cameroon.
Spain’s Primera Division attracted the most nominees with 18, followed by
England’s Premier League with 17 and Italy’s Serie A with 15. Four
nominees came from Germany’s Bundesliga and one from France’s Ligue 1.
The final FIFA/FIFPro World XI will be announced at the FIFA Ballon d’Or
gala in the Zurich Kongresshaus on 10 January 2011. During this televised
gala, the winner of the FIFA Ballon d’Or for the best player of 2010 and
the FIFA Women’s World Player of the Year 2010 award will also be revealed.
Meanwhile, the FIFA World Coach of the Year for Men’s Football award and
the FIFA World Coach of the Year for Women’s Football award will be
presented for the first time, while the FIFA Puskas Award for the best goal
of the year will be announced for the second year running. The FIFA
Presidential Award and the FIFA Fair Play Award will also be presented
during the gala.
The 55-player shortlist in full:
Goalkeepers: Gianluigi Buffon (Italy, Juventus FC), Iker Casillas (Spain,
Real Madrid C.F.), Petr Cech (Czech Republic, Chelsea FC), Julio Cesar
(Brazil, F.C. Internazionale), Edwin van der Sar (Netherlands, Manchester
United FC)
Defenders: Daniel Alves (Brazil, FC Barcelona), Gareth Bale (Wales,
Tottenham Hotspur), Michel Bastos (Brazil, Olympique Lyonnais), Ashley Cole
(England, Chelsea FC), Patrice Evra (France, Manchester United FC), Rio
Ferdinand (England, Manchester United FC), Philipp Lahm (Germany, FC Bayern
Munchen), Lucio (Brazil, F.C. Internazionale), Maicon (Brazil, F.C.
Internazionale), Marcelo (Brazil, Real Madrid C.F.), Alessandro Nesta
(Italy, AC Milan), Pepe (Portugal, Real Madrid C.F.), Gerard Pique (Spain,
FC Barcelona), Carles Puyol (Spain, FC Barcelona), Sergio Ramos (Spain, Real
Madrid C.F.), Walter Samuel (Argentina, F.C. Internazionale), John Terry
(England, Chelsea FC), Thiago Silva (Brazil, AC Milan), Nemanja Vidic
(Serbia, Manchester United FC), Javier Zanetti (Argentina, F.C.
Internazionale)
Midfielders: Esteban Cambiasso (Argentina, F.C. Internazionale), Michael
Essien (Ghana, Chelsea FC), Cesc Fabregas (Spain, Arsenal FC), Steven
Gerrard (England, Liverpool FC), Andres Iniesta (Spain, FC Barcelona),
Ricardo Kaka (Brazil, Real Madrid C.F.), Frank Lampard (England, Chelsea
FC), Javier Mascherano (Argentina, FC Barcelona), Thomas Muller (Germany, FC
Bayern Munchen), Mesut Ozil (Germany, Real Madrid C.F.), Andrea Pirlo
(Italy, AC Milan), Bastian Schweinsteiger (Germany, FC Bayern Munchen),
Wesley Sneijder (Netherlands, F.C. Internazionale), Xabi Alonso (Spain, Real
Madrid C.F.), Xavi (Spain, FC Barcelona)
Forwards: Dimitar Berbatov (Bulgaria, Manchester United FC), Didier Drogba
(Ivory Coast, Chelsea FC), Samuel Eto’o (Cameroon, F.C. Internazionale),
Diego Forlán (Uruguay, Atletico Madrid), Gonzalo Higuain (Argentina, Real
Madrid C.F.), Zlatan Ibrahimovic (Sweden, AC Milan), Lionel Messi
(Argentina, FC Barcelona), Diego Milito (Argentina, F.C. Internazionale),
Arjen Robben (Netherlands, FC Bayern München), Ronaldinho (Brazil, AC
Milan), Cristiano Ronaldo (Portugal, Real Madrid C.F.), Wayne Rooney
(England, Manchester United FC), Carlos Tevez (Argentina, Manchester City
FC), Fernando Torres (Spain, Liverpool FC), David Villa (Spain, FC Barcelona)
Thursday, July 1, 2010
如果还在一起
如果当我24岁时,
我们还在一起,
我们牵手去见彼此的家人,
获取他们的认同
如果当我26岁时,
我们还在一起,
我会挽起留了很久的长发,
做你最美的新娘
如果当我28岁时,
我们还在一起,
我们一起期待着迎接那个加入我们小家庭的新生命的降临
如果当我29岁时,
我们还在一起,
我们一起用心经营我们的家,
每天听着宝宝稚嫩的声音叫我们“爸爸”、“妈妈”
如果当我33岁时,
我们还在一起,
不管周围的人如何分分和和,
我们一起携手坚定的走过那3年之痛、7年之痒,
继续着我们的幸福
如果当我40岁时,
我们还在一起,
就算最初的激情已被现实的生活打磨殆尽,
一切归于平淡,
但彼此的目光仍然会追逐着对方的身影,
相视一笑也会觉得安心
如果当我50岁时,
我们还在一起,
孩子离开我们去追寻他的幸福,
虽然想念宝宝,
依然还有你陪在我的身边,
每天傍晚手牵手一起散步
如果当我60岁时,
我们还在一起,
我们都已该休息,
有了大把的时间一起去做彼此曾经想做而没做的事,
去想去而没去过的地方
如果当我70岁时,
我们还在一起,
身边的孩子们都已经称呼我们“爷爷”、“奶奶”,
你还是当我是个不会照顾自己的孩子,
呵护着你眼中的“孩子”
如果当我76岁时,
我们还在一起,
我们要通知所以认识的人,
邀请所有的人来参加我们的金婚纪念日,
分享我们的幸福快乐
如果当我80岁时,
我们还在一起,
我们会每天躺在摇椅上一起晒太阳,
虽然不知道生命会持续到哪一天,
因为身边有彼此的陪伴,
不再恐惧死亡,
享受生命中的每一天
如果当我走到生命的最后一天时,
我希望身边有你陪伴,
我不要做那个留下来的人,
请允许我自私的先离开这个世界,
又或者你坚持不了了,我愿意陪你一同远去...
因为,
没有你的世界是冰冷的,
所以,
亲爱的,
如果到了那一天,
请让我先走,或带上我一起,
因为,
曾经属于
两个人共享的幸福我一个人收纳不了......
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
死生契阔 与子相悦 执子之手 与子偕老 才是幸福
我们还在一起,
我们牵手去见彼此的家人,
获取他们的认同
如果当我26岁时,
我们还在一起,
我会挽起留了很久的长发,
做你最美的新娘
如果当我28岁时,
我们还在一起,
我们一起期待着迎接那个加入我们小家庭的新生命的降临
如果当我29岁时,
我们还在一起,
我们一起用心经营我们的家,
每天听着宝宝稚嫩的声音叫我们“爸爸”、“妈妈”
如果当我33岁时,
我们还在一起,
不管周围的人如何分分和和,
我们一起携手坚定的走过那3年之痛、7年之痒,
继续着我们的幸福
如果当我40岁时,
我们还在一起,
就算最初的激情已被现实的生活打磨殆尽,
一切归于平淡,
但彼此的目光仍然会追逐着对方的身影,
相视一笑也会觉得安心
如果当我50岁时,
我们还在一起,
孩子离开我们去追寻他的幸福,
虽然想念宝宝,
依然还有你陪在我的身边,
每天傍晚手牵手一起散步
如果当我60岁时,
我们还在一起,
我们都已该休息,
有了大把的时间一起去做彼此曾经想做而没做的事,
去想去而没去过的地方
如果当我70岁时,
我们还在一起,
身边的孩子们都已经称呼我们“爷爷”、“奶奶”,
你还是当我是个不会照顾自己的孩子,
呵护着你眼中的“孩子”
如果当我76岁时,
我们还在一起,
我们要通知所以认识的人,
邀请所有的人来参加我们的金婚纪念日,
分享我们的幸福快乐
如果当我80岁时,
我们还在一起,
我们会每天躺在摇椅上一起晒太阳,
虽然不知道生命会持续到哪一天,
因为身边有彼此的陪伴,
不再恐惧死亡,
享受生命中的每一天
如果当我走到生命的最后一天时,
我希望身边有你陪伴,
我不要做那个留下来的人,
请允许我自私的先离开这个世界,
又或者你坚持不了了,我愿意陪你一同远去...
因为,
没有你的世界是冰冷的,
所以,
亲爱的,
如果到了那一天,
请让我先走,或带上我一起,
因为,
曾经属于
两个人共享的幸福我一个人收纳不了......
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
死生契阔 与子相悦 执子之手 与子偕老 才是幸福
Tuesday, June 8, 2010
EP-LDA 0.2 更正版!!!
这次主要debug了一下Gamma函数,原先计算Scaler的时候直接套用Gamma Function的定义计算,容易导致溢出(用Matlab算几个值就知道了),这次改为用log_gamma()进行计算,避开计算Gamma函数的乘积。貌似这次效果要好些,但是应该还是会有bug,以后再慢慢调不着急嘿嘿。
贴个链接:https://www.cs.indiana.edu/~kduan/rsc/2010/lda-ep-0.2.tar
贴个链接:https://www.cs.indiana.edu/~kduan/rsc/2010/lda-ep-0.2.tar
Monday, June 7, 2010
EP-LDA!!!
从开始看LDA到最后初步写完了基于EP的LDA算法!前前后后花了将近三周?忘了,反正很长。。。刚开始时候看LDA的那叫个一头雾水啊。。看到最后才发现,好像不是因为很难,而是自己懂的东西太少了。。Blei的那篇文章从头到尾看下来,发现要是不好好学一下Graphical Model和Machine Learning的话那是基本上在这个方向发展无望的,当然还有最优化相关的知识吧。。。Anyway,今天整理了下代码,感觉还不错嘿嘿。。(狞笑)
废话少说,贴出来几个很有用的reference,算是又一个reading list吧。。。
1. http://research.microsoft.com/en-us/um/people/minka/papers/ep/
这个是Minka所有关于EP的paper list,怎么说的,非常想感慨的一下是,这样的人之所以能有这样好的idea,可能和美国对孩子的教育方式是很有关系的,中国的孩子学习能力超强的,但是又有什么用呢,总是会被别人牵着鼻子走,很难会有很创新的idea。。想到刚刚发布的iphone 4和大陆那么多代工工厂,不禁汗一下,难道中国人生来就是“任劳任怨”的么。。。好像扯淡扯远了,let's make idea!!!
2. http://www.cs.princeton.edu/~blei/.../BleiNgJordan2003.pdf
LDA的开篇之作,没啥可说的,自己写了一个learning notes也一并贴出来,当然写的很简陋,仅仅是这篇paper里边我感觉比较难的地方的推导过程(又一个只会学习的!)请见这里:https://www.cs.indiana.edu/~kduan/rsc/2010/lda-report.pdf
3. http://chasen.org/~daiti-m/dist/lda/
代码框架借鉴的是这位大神,这个是用variational inference也就是原始paper里边的推理方法。代码写的相对来说比较容易懂,所以就没有用Blei自己release的代码,那个应该是写的很完美的,可是比较难理解,对本人这样的菜鸟还是留着以后慢慢研究,哈哈
废话少说,贴出来几个很有用的reference,算是又一个reading list吧。。。
1. http://research.microsoft.com/en-us/um/people/minka/papers/ep/
这个是Minka所有关于EP的paper list,怎么说的,非常想感慨的一下是,这样的人之所以能有这样好的idea,可能和美国对孩子的教育方式是很有关系的,中国的孩子学习能力超强的,但是又有什么用呢,总是会被别人牵着鼻子走,很难会有很创新的idea。。想到刚刚发布的iphone 4和大陆那么多代工工厂,不禁汗一下,难道中国人生来就是“任劳任怨”的么。。。好像扯淡扯远了,let's make idea!!!
2. http://www.cs.princeton.edu/~blei/.../BleiNgJordan2003.pdf
LDA的开篇之作,没啥可说的,自己写了一个learning notes也一并贴出来,当然写的很简陋,仅仅是这篇paper里边我感觉比较难的地方的推导过程(又一个只会学习的!)请见这里:https://www.cs.indiana.edu/~kduan/rsc/2010/lda-report.pdf
3. http://chasen.org/~daiti-m/dist/lda/
代码框架借鉴的是这位大神,这个是用variational inference也就是原始paper里边的推理方法。代码写的相对来说比较容易懂,所以就没有用Blei自己release的代码,那个应该是写的很完美的,可是比较难理解,对本人这样的菜鸟还是留着以后慢慢研究,哈哈
Friday, May 28, 2010
Bias-Variance Tradeoff
Bias(偏差)是指真正的均值和预测值之间的差值;Variance(方差)是指这个预测值作为随机变量的方差(在所有可能的训练样本上平均). 如果用公式表示,就是:
Bias(f^(x_0))=E(f^(x_0))-f(x_0)
Var(f^(x_0))=E[f^(x_0)-E[f^(x_0)]]^2
举个例子,k-NN的方差随着k的上升而下降。这表示了k-NN估计的"稳定性"随着k的上升而提高;而k越高,取的邻域就越大,用这个大邻域中的均值去估计f(x0),偏差就会增大。Bias表示预测的"准确程度";而Variance表示预测的"稳定性".
下边是一个经典的关于Bias-Variance的曲线图:
(model complexity可以理解成这个分类器输入的维度,k-NN中,k越大,复杂度就越低,即分类越粗糙;k越小,复杂度越 高,即分类越细腻)
高,即分类越细腻)
Bias(f^(x_0))=E(f^(x_0))-f(x_0)
Var(f^(x_0))=E[f^(x_0)-E[f^(x_0)]]^2
举个例子,k-NN的方差随着k的上升而下降。这表示了k-NN估计的"稳定性"随着k的上升而提高;而k越高,取的邻域就越大,用这个大邻域中的均值去估计f(x0),偏差就会增大。Bias表示预测的"准确程度";而Variance表示预测的"稳定性".
下边是一个经典的关于Bias-Variance的曲线图:
(model complexity可以理解成这个分类器输入的维度,k-NN中,k越大,复杂度就越低,即分类越粗糙;k越小,复杂度越
 高,即分类越细腻)
高,即分类越细腻)
Tuesday, May 25, 2010
国史大纲 前言
凡读本书请先具下列诸信念:
一、当信任何一国之国民,尤其是自称知识在水平线以上之国民,对其本国已往历史,应该略有所知。(否则最多只算一有知识的人,不能算一有知识的国民。)
二、所谓对其本国已往历史略有所知者,尤必附随一种对其本国已往历史之温情与敬意。(否则只算知道了一些外国史,不得云对本国史有知识。)
三、所谓对其本国已往历史有一种温情与敬意者,至少不会对其本国历史抱一种偏激的虚无主义,(即视本国已往历史为无一点有价值,亦无一处足以使彼满意。) 亦至少不会感到现在我们是站在已往历史最高之顶点,(此乃一种浅薄狂妄的进化观。)而将我们当身种种罪恶与弱点,一切诿卸于古人。(此乃一种似是而非之文化自谴。)
四、当信每一国家必待其国民具备上列诸条件者比较渐多,其国家乃再有向前发展之希望。(否则其所改进,等于一个被征服国或次殖民地之改进,对其自身国家不发生关系。换言之,此种改进,无异是一种变相的文化征服,乃其文化自身之萎缩与消灭,并非其文化自身之转变与发皇。)
一、当信任何一国之国民,尤其是自称知识在水平线以上之国民,对其本国已往历史,应该略有所知。(否则最多只算一有知识的人,不能算一有知识的国民。)
二、所谓对其本国已往历史略有所知者,尤必附随一种对其本国已往历史之温情与敬意。(否则只算知道了一些外国史,不得云对本国史有知识。)
三、所谓对其本国已往历史有一种温情与敬意者,至少不会对其本国历史抱一种偏激的虚无主义,(即视本国已往历史为无一点有价值,亦无一处足以使彼满意。) 亦至少不会感到现在我们是站在已往历史最高之顶点,(此乃一种浅薄狂妄的进化观。)而将我们当身种种罪恶与弱点,一切诿卸于古人。(此乃一种似是而非之文化自谴。)
四、当信每一国家必待其国民具备上列诸条件者比较渐多,其国家乃再有向前发展之希望。(否则其所改进,等于一个被征服国或次殖民地之改进,对其自身国家不发生关系。换言之,此种改进,无异是一种变相的文化征服,乃其文化自身之萎缩与消灭,并非其文化自身之转变与发皇。)
Friday, May 14, 2010
这几天准备的Reading List
1. Classical Probabilistic Models and Conditional Random Field, K. Roman et al,
http://www.scai.fraunhofer.de/fileadmin/images/bio/data_mining/paper/crf_klinger_tomanek.pdf
2. A Tutorial Introduction to Belief Propagation (crv09), James Coughlan
http://computerrobotvision.org/2009/tutorial_day/crv09_belief_propagation_v2.pdf
3. Understanding Belief Propagation and its Generalizations, Weiss,
http://portal.acm.org/citation.cfm?id=779352
4. Efficient Belief Propagation for Early Vision, PEDRO F. FELZENSZWALB and DANIEL P. HUTTENLOCHER,
http://www.cs.cornell.edu/~dph/papers/bp-cvpr.pdf
5. Fractional Belief Propagation (NIPS02), W. Wiegerinck et al.
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.69.8426
6. Nonparametric Belief Propagation, Erik B. Sudderth et al.
http://ssg.mit.edu/~esuddert/papers/cvpr03.pdf
7. Data Driven Mean-Shift Belief Propagation For non-Gaussian MRFs(CVPR10), Minwoo Park et al.
http://vision.cse.psu.edu/paper/CVPR2010DDMSBP0291.pdf
8. A Constant-Space Belief Propagation Algorithm for Stereo Matching(CVPR10), Qingxiong Yang et al.
http://vision.ai.uiuc.edu/~qyang6/publications/cvpr-10-qingxiong-yang-csbp.pdf
9. Residual Belief Propagation: Informed Scheduling for Asynchronous Message Passing(UAI06), G Elidan et al.
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.129.1828
这两天读完了前三篇,对BP和Graphical Model的理解比原来更清楚了,我简单写了一点总结。以下:
第一篇是一个Techinical Report,主要介绍了Graphical Model的一般概念,以及四种常见的Graphical Model和它们之间的相互关系。这几种Model分别为Naive Bayes Model, HMM Model, Maximum Entropy Model, Conditional Random Field. HMM是序列化的Naive Bayes,它们都属于Generative Model;而条件随机场则是序列化的最大熵模型,它们都属于判别模型(Discriminate Model)。生成模型和判别模型之间的区别在这里也有介绍。文章详细介绍了前三种模型的推导过程。在推导最大熵模型的时候,本文仅给出了最大熵模型对应的最优条件概率分布,但是没有指明Feature Function的权值lambda如何求。其实在这一点上,最大熵模型的求解非常类似SVM的最优话Margin的过程,在参数估计的时候用到的都是拉格朗日对偶式(Lagrange Duality)和凸优化的知识,具体参数求解过程可参考SVM的推导过程(Stanford CS229课程讲义)。
然后本文介绍了Graphical Model的分类(Undirected和Directed)。很显然NB和HMM属于有向图,而 Undirected Graphical Model我理解其实就是Markov Random Field。另外Factor Graph在文章中也有介绍,但是更详细的如何构造Factor Graph以及如何在Factor Graph和Bayes Network或MRF之间转换则在第三篇文章中有论述。还有一点,MRF也是表征一个Joint Distribution,CRF对应的是表征一个Conditional Distribution;MRF我理解其实是一个二维的HMM,CRF则是一个二维的Linear CRF。。。是不是很别扭。。不过应该是这样的。
本文的后半部分集中讨论了CRF,主要是Linear CRF的构造,训练,和推理。Linear CRF (L-CRF)的构造表征的是,给定一组Observation之后的一个隐藏变量序列的概率。L-CRF与HMM的区别是,L-CRF是对一个条件概率建模,而 HMM是对一个联合概率建模;而且HMM要求当前的Observation只和当前的Hidden Variable相关,而与其它Hidden Variabl是条件独立的,即别的时刻的隐藏变量不影响我当前的观测结果。但是L-CRF 放松了这一要求,允许更多的dependency出现,模型更加灵活。构建模型之前,L-CRF被转换成Factor Graph,每一个Factor都是一组特征函数的线性组合之后的指数形式,这一点与最大熵模型类似。本文讨论的训练L-CRF模型的方法是MAP方法,与MLE的区别是增加了一个关于参数lambda的先验分布,用来避免 overfitting的情况。而在进行推理时,本文采用的是与HMM中相同的Viterbi算法,用于求出给定 Observation后最可能的一个隐藏序列。其实我感觉BP算法的max-product版本和Viterbi算法非常类似。
第二篇是BP算法的一个Tutorial,主要重点如下:
第一,对于Factor的理解。在一个Bayes Network或者HMM等Directed Graphical Model中,Factor可以理解成各个变量节点的条件概率分布,我认为在这里可以理解成,一个factor对应于一个节点的CPT(条件概率表);但是在MRF等Undirected Graphical Model中,节点之间没有明确的条件概率关系,这时候Factor就可以理解成是一个关于若干变量的Compatibility Function,可以理解成描述节点之间的相互作用或者节点本身的特性。比如在MRF中,我的理解是,每个节点都是被两种因素影响,一个是和周围neighbor节点们的相互作用,另一个是节点本身的“势能”,也即Hidden Variable和对应Observed Variable之间的相互关系,因为观测值是已知的,所以可以把它们之间的相互关系类比成一种“势能”。
第二,明确了研究MRF或者Bayes Nets的目的,即求隐藏变量的Marginalized Probability和求使一个联合分布最大化的一组隐藏变量的取值。
第三,介绍的BP的基本形式,是一种Messsage Passing算法,本质即是通过不断地迭代求局部最佳值来最终获得全局的一组变量取值。如果图结构中不存在环(loop),则 BP算法是确定推理;若存在环结构,则BP算法成为一种近似推理。我对此的理解是,如果不存在环,则这张图一定存在若干“入口”(比如Bayes Nets的Root节点们),可先从这些“入口”节点入手,求出这些节点对应的Belief,然后将这些Belief 顺次传递message给其它节点;但是如果图结构中有环,则必须首先随机初始化所有message,然后通过迭代的方法求出最终解。那么这样看的话,BP算法和其它很多Gradient Descent算法(如EM,Hill Climbing算法等)共同的问题就是无法保证一定会获得全局最优解,而且这些迭代算法本身需要的迭代时间也会比较长。所以这样就有两个BP算法的研究方向,一个是如何保证或者尽量求得全局最优解,一个是如何减少迭代计算的开销。
具体的Belief计算方法和Message更新算法我省略掉,可以参考原文,实现起来应该不是太复杂。本文最后给出的一个例子就是利用BP算法解决Stereo Matching,以及若干改进建议。
第三篇文章是Weiss的一个technical report,引用次数很高。这篇文章侧重于揭示BP算法的本质,用热力学中的模型和概率图模型进行类比,说明了BP算法的物理意义。本文的讨论主要基于Pairwise Markov Random Field,由一个stereo matching的例子引出了其基本模型。这篇文章详细说明了如何将Pairwise MRF、Bayes Nets和Factor Graph之间的相互转换,并最终在MRF上对BP算法进行讨论,这样的好处是,MRF是无向的,而且Message Upadate只有一种形式(与Factor Graph不同)。
一个节点的Belief由以下因素决定:节点本身的Local Evidence(即该节点和对应的观测变量之间的关系,用Compatibility Function表示);该节点的neighbor节点向这个节点传送的message的乘积。Message的更新函数也类似:由节点i向节点j传送的message由不包括j的和节点i相邻的节点向节点i发送的message之积,节点i本身的特性(Local Evidence),以及节点i和节点j之间的相互关系共同决定。文章稍后给出了更一般的形式,即message的更新其实是节点belief的marginalization的过程,即bi = sigma(j)bij。更一般地,文章还给出了多节点Belief的形式及其message如何更新,这个是后面文章所讲的GBP(Generalized Belief Propagation)的基础。
这篇文章另一个重点是讨论了热力学的几个能量模型及它们和BP/GBP算法之间的对应关系。文章首先介绍了玻尔兹曼定律,即系统的均衡分布由系统的能量状态和温度共同决定。接下来,根据不同的assumption,作者讨论了两种形式的自由能,即Mean-Field Free Energy和Bethe Free Energy。其中,后者假定Gibbs自由能下的Belief满足Normalization Condition以及Marginalization Condition,因而BP算法和Bethe Approximation是等价的。
最后,本文讨论了Generalized Belief Propagation。这是与物理学中Kikuchi Approximation等价的,可以看作是Bethe Approximation的一种扩展形式。具体细节参见原文,其主要思想是,将一个graph分成不同的region以及它们的sub-region,并由这些cluster构造一个新的graph,在这个新构造的graph上进行BP算法(用到之前介绍的多节点的BP形式),这样做的好处是,推理过程中图的节点数量变少了,而且多节点的Belief形式比单个节点的Belief表达信息要多,所以效果应该会更好。
http://www.scai.fraunhofer.de/fileadmin/images/bio/data_mining/paper/crf_klinger_tomanek.pdf
2. A Tutorial Introduction to Belief Propagation (crv09), James Coughlan
http://computerrobotvision.org/2009/tutorial_day/crv09_belief_propagation_v2.pdf
3. Understanding Belief Propagation and its Generalizations, Weiss,
http://portal.acm.org/citation.cfm?id=779352
4. Efficient Belief Propagation for Early Vision, PEDRO F. FELZENSZWALB and DANIEL P. HUTTENLOCHER,
http://www.cs.cornell.edu/~dph/papers/bp-cvpr.pdf
5. Fractional Belief Propagation (NIPS02), W. Wiegerinck et al.
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.69.8426
6. Nonparametric Belief Propagation, Erik B. Sudderth et al.
http://ssg.mit.edu/~esuddert/papers/cvpr03.pdf
7. Data Driven Mean-Shift Belief Propagation For non-Gaussian MRFs(CVPR10), Minwoo Park et al.
http://vision.cse.psu.edu/paper/CVPR2010DDMSBP0291.pdf
8. A Constant-Space Belief Propagation Algorithm for Stereo Matching(CVPR10), Qingxiong Yang et al.
http://vision.ai.uiuc.edu/~qyang6/publications/cvpr-10-qingxiong-yang-csbp.pdf
9. Residual Belief Propagation: Informed Scheduling for Asynchronous Message Passing(UAI06), G Elidan et al.
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.129.1828
这两天读完了前三篇,对BP和Graphical Model的理解比原来更清楚了,我简单写了一点总结。以下:
第一篇是一个Techinical Report,主要介绍了Graphical Model的一般概念,以及四种常见的Graphical Model和它们之间的相互关系。这几种Model分别为Naive Bayes Model, HMM Model, Maximum Entropy Model, Conditional Random Field. HMM是序列化的Naive Bayes,它们都属于Generative Model;而条件随机场则是序列化的最大熵模型,它们都属于判别模型(Discriminate Model)。生成模型和判别模型之间的区别在这里也有介绍。文章详细介绍了前三种模型的推导过程。在推导最大熵模型的时候,本文仅给出了最大熵模型对应的最优条件概率分布,但是没有指明Feature Function的权值lambda如何求。其实在这一点上,最大熵模型的求解非常类似SVM的最优话Margin的过程,在参数估计的时候用到的都是拉格朗日对偶式(Lagrange Duality)和凸优化的知识,具体参数求解过程可参考SVM的推导过程(Stanford CS229课程讲义)。
然后本文介绍了Graphical Model的分类(Undirected和Directed)。很显然NB和HMM属于有向图,而 Undirected Graphical Model我理解其实就是Markov Random Field。另外Factor Graph在文章中也有介绍,但是更详细的如何构造Factor Graph以及如何在Factor Graph和Bayes Network或MRF之间转换则在第三篇文章中有论述。还有一点,MRF也是表征一个Joint Distribution,CRF对应的是表征一个Conditional Distribution;MRF我理解其实是一个二维的HMM,CRF则是一个二维的Linear CRF。。。是不是很别扭。。不过应该是这样的。
本文的后半部分集中讨论了CRF,主要是Linear CRF的构造,训练,和推理。Linear CRF (L-CRF)的构造表征的是,给定一组Observation之后的一个隐藏变量序列的概率。L-CRF与HMM的区别是,L-CRF是对一个条件概率建模,而 HMM是对一个联合概率建模;而且HMM要求当前的Observation只和当前的Hidden Variable相关,而与其它Hidden Variabl是条件独立的,即别的时刻的隐藏变量不影响我当前的观测结果。但是L-CRF 放松了这一要求,允许更多的dependency出现,模型更加灵活。构建模型之前,L-CRF被转换成Factor Graph,每一个Factor都是一组特征函数的线性组合之后的指数形式,这一点与最大熵模型类似。本文讨论的训练L-CRF模型的方法是MAP方法,与MLE的区别是增加了一个关于参数lambda的先验分布,用来避免 overfitting的情况。而在进行推理时,本文采用的是与HMM中相同的Viterbi算法,用于求出给定 Observation后最可能的一个隐藏序列。其实我感觉BP算法的max-product版本和Viterbi算法非常类似。
第二篇是BP算法的一个Tutorial,主要重点如下:
第一,对于Factor的理解。在一个Bayes Network或者HMM等Directed Graphical Model中,Factor可以理解成各个变量节点的条件概率分布,我认为在这里可以理解成,一个factor对应于一个节点的CPT(条件概率表);但是在MRF等Undirected Graphical Model中,节点之间没有明确的条件概率关系,这时候Factor就可以理解成是一个关于若干变量的Compatibility Function,可以理解成描述节点之间的相互作用或者节点本身的特性。比如在MRF中,我的理解是,每个节点都是被两种因素影响,一个是和周围neighbor节点们的相互作用,另一个是节点本身的“势能”,也即Hidden Variable和对应Observed Variable之间的相互关系,因为观测值是已知的,所以可以把它们之间的相互关系类比成一种“势能”。
第二,明确了研究MRF或者Bayes Nets的目的,即求隐藏变量的Marginalized Probability和求使一个联合分布最大化的一组隐藏变量的取值。
第三,介绍的BP的基本形式,是一种Messsage Passing算法,本质即是通过不断地迭代求局部最佳值来最终获得全局的一组变量取值。如果图结构中不存在环(loop),则 BP算法是确定推理;若存在环结构,则BP算法成为一种近似推理。我对此的理解是,如果不存在环,则这张图一定存在若干“入口”(比如Bayes Nets的Root节点们),可先从这些“入口”节点入手,求出这些节点对应的Belief,然后将这些Belief 顺次传递message给其它节点;但是如果图结构中有环,则必须首先随机初始化所有message,然后通过迭代的方法求出最终解。那么这样看的话,BP算法和其它很多Gradient Descent算法(如EM,Hill Climbing算法等)共同的问题就是无法保证一定会获得全局最优解,而且这些迭代算法本身需要的迭代时间也会比较长。所以这样就有两个BP算法的研究方向,一个是如何保证或者尽量求得全局最优解,一个是如何减少迭代计算的开销。
具体的Belief计算方法和Message更新算法我省略掉,可以参考原文,实现起来应该不是太复杂。本文最后给出的一个例子就是利用BP算法解决Stereo Matching,以及若干改进建议。
第三篇文章是Weiss的一个technical report,引用次数很高。这篇文章侧重于揭示BP算法的本质,用热力学中的模型和概率图模型进行类比,说明了BP算法的物理意义。本文的讨论主要基于Pairwise Markov Random Field,由一个stereo matching的例子引出了其基本模型。这篇文章详细说明了如何将Pairwise MRF、Bayes Nets和Factor Graph之间的相互转换,并最终在MRF上对BP算法进行讨论,这样的好处是,MRF是无向的,而且Message Upadate只有一种形式(与Factor Graph不同)。
一个节点的Belief由以下因素决定:节点本身的Local Evidence(即该节点和对应的观测变量之间的关系,用Compatibility Function表示);该节点的neighbor节点向这个节点传送的message的乘积。Message的更新函数也类似:由节点i向节点j传送的message由不包括j的和节点i相邻的节点向节点i发送的message之积,节点i本身的特性(Local Evidence),以及节点i和节点j之间的相互关系共同决定。文章稍后给出了更一般的形式,即message的更新其实是节点belief的marginalization的过程,即bi = sigma(j)bij。更一般地,文章还给出了多节点Belief的形式及其message如何更新,这个是后面文章所讲的GBP(Generalized Belief Propagation)的基础。
这篇文章另一个重点是讨论了热力学的几个能量模型及它们和BP/GBP算法之间的对应关系。文章首先介绍了玻尔兹曼定律,即系统的均衡分布由系统的能量状态和温度共同决定。接下来,根据不同的assumption,作者讨论了两种形式的自由能,即Mean-Field Free Energy和Bethe Free Energy。其中,后者假定Gibbs自由能下的Belief满足Normalization Condition以及Marginalization Condition,因而BP算法和Bethe Approximation是等价的。
最后,本文讨论了Generalized Belief Propagation。这是与物理学中Kikuchi Approximation等价的,可以看作是Bethe Approximation的一种扩展形式。具体细节参见原文,其主要思想是,将一个graph分成不同的region以及它们的sub-region,并由这些cluster构造一个新的graph,在这个新构造的graph上进行BP算法(用到之前介绍的多节点的BP形式),这样做的好处是,推理过程中图的节点数量变少了,而且多节点的Belief形式比单个节点的Belief表达信息要多,所以效果应该会更好。
Tuesday, May 11, 2010
概率图模型一点点总结(2)
判别模型 和 生成模型
【摘要】
- 生成模型:无穷样本==》概率密度模型 = 产生模型==》预测
- 判别模型:有限样本==》判别函数 = 预测模型==》预测
【简介】
简单的说,假设o是观察值,q是模型。
如果对P(o|q)建模,就是Generative模型。其基本思想是首先建立样本的概率密度模型,再利用模型进行推理预测。要求已知样本无穷或尽可能的大限制。
这种方法一般建立在统计力学和bayes理论的基础之上。
如果对条件概率(后验概率) P(q|o)建模,就是Discrminative模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。代表性理论为统计学习理论。
这两种方法目前交叉较多。
【判别模型Discriminative Model】——inter-class probabilistic description
又可以称为条件模型,或条件概率模型。估计的是条件概率分布 (conditional distribution), p(class|context)。
利用正负例和分类标签,focus在判别模型的边缘分布。目标函数直接对应于分类准确率。
- 主要特点:
寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。
- 优点:
分类边界更灵活,比使用纯概率方法或生产模型得到的更高级。
能清晰的分辨出多类或某一类与其他类之间的差异特征
在聚类、viewpoint changes, partial occlusion and scale variations中的效果较好
适用于较多类别的识别
判别模型的性能比生成模型要简单,比较容易学习
- 缺点:
不能反映训练数据本身的特性。能力有限,可以告诉你的是1还是2,但没有办法把整个场景描述出来。
Lack elegance of generative: Priors, 结构, 不确定性
Alternative notions of penalty functions, regularization, 核函数
黑盒操作: 变量间的关系不清楚,不可视
- 常见的主要有:
logistic regression
SVMs
traditional neural networks
Nearest neighbor
Conditional random fields(CRF): 目前最新提出的热门模型,从NLP领域产生的,正在向ASR和CV上发展。
- 主要应用:
Image and document classification
Biosequence analysis
Time series prediction
【生成模型Generative Model】——intra-class probabilistic description
又叫产生式模型。估计的是联合概率分布(joint probability distribution),p(class, context)=p(class|context)*p(context)。
用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。在机器学习中,或用于直接对数据建模(用概率密度函数对观察到的draw建模),或作为生成条件概率密度函数的中间步骤。通过使用贝叶斯rule可以从生成模型中得到条件分布。
如果观察到的数据是完全由生成模型所生成的,那么就可以 fitting生成模型的参数,从而仅可能的增加数据相似度。但数据很少能由生成模型完全得到,所以比较准确的方式是直接对条件密度函数建模,即使用分类或回归分析。
与描述模型的不同是,描述模型中所有变量都是直接测量得到。
- 主要特点:
一般主要是对后验概率建模,从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。
只关注自己的inclass本身(即点左下角区域内的概率),不关心到底 decision boundary在哪。
- 优点:
实际上带的信息要比判别模型丰富,
研究单类问题比判别模型灵活性强
模型可以通过增量学习得到
能用于数据不完整(missing data)情况
modular construction of composed solutions to complex problems
prior knowledge can be easily taken into account
robust to partial occlusion and viewpoint changes
can tolerate significant intra-class variation of object appearance
- 缺点:
tend to produce a significant number of false positives. This is particularly true for object classes which share a high visual similarity such as horses and cows
学习和计算过程比较复杂
- 常见的主要有:
Gaussians, Naive Bayes, Mixtures of multinomials
Mixtures of Gaussians, Mixtures of experts, HMMs
Sigmoidal belief networks, Bayesian networks
Markov random fields
所列举的Generative model也可以用disriminative方法来训练,比如GMM或HMM,训练的方法有EBW(Extended Baum Welch),或最近Fei Sha提出的Large Margin方法。
- 主要应用:
NLP:
Traditional rule-based or Boolean logic systems (Dialog and Lexis-Nexis) are giving way to statistical approaches (Markov models and stochastic context grammars)
Medical Diagnosis:
QMR knowledge base, initially a heuristic expert systems for reasoning about diseases and symptoms been augmented with decision theoretic formulation Genomics and Bioinformatics
Sequences represented as generative HMMs
【两者之间的关系】
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
Can performance of SVMs be combined elegantly with flexible Bayesian statistics?
Maximum Entropy Discrimination marries both methods: Solve over a distribution of parameters (a distribution over solutions)
【参考网址】
http://prfans.com/forum/viewthread.php?tid=80
http://hi.baidu.com/cat_ng/blog/item/5e59c3cea730270593457e1d.html
http://en.wikipedia.org/wiki/Generative_model
http://blog.csdn.net/yangleecool/archive/2009/04/05/4051029.aspx
==================
比较三种模型:HMMs and MRF and CRF
http://blog.sina.com.cn/s/blog_4cdaefce010082rm.html
HMMs(隐马尔科夫模型):
状态序列不能直接被观测到(hidden);
每一个观测被认为是状态序列的随机函数;
状态转移矩阵是随机函数,根据转移概率矩阵来改变状态。
HMMs与MRF的区别是只包含标号场变量,不包括观测场变量。
MRF(马尔科夫随机场)
将图像模拟成一个随机变量组成的网格。
其中的每一个变量具有明确的对由其自身之外的随机变量组成的近邻的依赖性(马尔科夫性)。
CRF(条件随机场),又称为马尔可夫随机域
一种用于标注和切分有序数据的条件概率模型。
从形式上来说CRF可以看做是一种无向图模型,考察给定输入序列的标注序列的条件概率。
在视觉问题的应用:
HMMs:图像去噪、图像纹理分割、模糊图像复原、纹理图像检索、自动目标识别等
MRF: 图像恢复、图像分割、边缘检测、纹理分析、目标匹配和识别等
CRF: 目标检测、识别、序列图像中的目标分割
P.S.
标号场为隐随机场,它描述像素的局部相关属性,采用的模型应根据人们对图像的结构与特征的认识程度,具有相当大的灵活性。
空域标号场的先验模型主要有非因果马尔可夫模型和因果马尔可夫模型。
【摘要】
- 生成模型:无穷样本==》概率密度模型 = 产生模型==》预测
- 判别模型:有限样本==》判别函数 = 预测模型==》预测
【简介】
简单的说,假设o是观察值,q是模型。
如果对P(o|q)建模,就是Generative模型。其基本思想是首先建立样本的概率密度模型,再利用模型进行推理预测。要求已知样本无穷或尽可能的大限制。
这种方法一般建立在统计力学和bayes理论的基础之上。
如果对条件概率(后验概率) P(q|o)建模,就是Discrminative模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。代表性理论为统计学习理论。
这两种方法目前交叉较多。
【判别模型Discriminative Model】——inter-class probabilistic description
又可以称为条件模型,或条件概率模型。估计的是条件概率分布 (conditional distribution), p(class|context)。
利用正负例和分类标签,focus在判别模型的边缘分布。目标函数直接对应于分类准确率。
- 主要特点:
寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。
- 优点:
分类边界更灵活,比使用纯概率方法或生产模型得到的更高级。
能清晰的分辨出多类或某一类与其他类之间的差异特征
在聚类、viewpoint changes, partial occlusion and scale variations中的效果较好
适用于较多类别的识别
判别模型的性能比生成模型要简单,比较容易学习
- 缺点:
不能反映训练数据本身的特性。能力有限,可以告诉你的是1还是2,但没有办法把整个场景描述出来。
Lack elegance of generative: Priors, 结构, 不确定性
Alternative notions of penalty functions, regularization, 核函数
黑盒操作: 变量间的关系不清楚,不可视
- 常见的主要有:
logistic regression
SVMs
traditional neural networks
Nearest neighbor
Conditional random fields(CRF): 目前最新提出的热门模型,从NLP领域产生的,正在向ASR和CV上发展。
- 主要应用:
Image and document classification
Biosequence analysis
Time series prediction
【生成模型Generative Model】——intra-class probabilistic description
又叫产生式模型。估计的是联合概率分布(joint probability distribution),p(class, context)=p(class|context)*p(context)。
用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。在机器学习中,或用于直接对数据建模(用概率密度函数对观察到的draw建模),或作为生成条件概率密度函数的中间步骤。通过使用贝叶斯rule可以从生成模型中得到条件分布。
如果观察到的数据是完全由生成模型所生成的,那么就可以 fitting生成模型的参数,从而仅可能的增加数据相似度。但数据很少能由生成模型完全得到,所以比较准确的方式是直接对条件密度函数建模,即使用分类或回归分析。
与描述模型的不同是,描述模型中所有变量都是直接测量得到。
- 主要特点:
一般主要是对后验概率建模,从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。
只关注自己的inclass本身(即点左下角区域内的概率),不关心到底 decision boundary在哪。
- 优点:
实际上带的信息要比判别模型丰富,
研究单类问题比判别模型灵活性强
模型可以通过增量学习得到
能用于数据不完整(missing data)情况
modular construction of composed solutions to complex problems
prior knowledge can be easily taken into account
robust to partial occlusion and viewpoint changes
can tolerate significant intra-class variation of object appearance
- 缺点:
tend to produce a significant number of false positives. This is particularly true for object classes which share a high visual similarity such as horses and cows
学习和计算过程比较复杂
- 常见的主要有:
Gaussians, Naive Bayes, Mixtures of multinomials
Mixtures of Gaussians, Mixtures of experts, HMMs
Sigmoidal belief networks, Bayesian networks
Markov random fields
所列举的Generative model也可以用disriminative方法来训练,比如GMM或HMM,训练的方法有EBW(Extended Baum Welch),或最近Fei Sha提出的Large Margin方法。
- 主要应用:
NLP:
Traditional rule-based or Boolean logic systems (Dialog and Lexis-Nexis) are giving way to statistical approaches (Markov models and stochastic context grammars)
Medical Diagnosis:
QMR knowledge base, initially a heuristic expert systems for reasoning about diseases and symptoms been augmented with decision theoretic formulation Genomics and Bioinformatics
Sequences represented as generative HMMs
【两者之间的关系】
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
Can performance of SVMs be combined elegantly with flexible Bayesian statistics?
Maximum Entropy Discrimination marries both methods: Solve over a distribution of parameters (a distribution over solutions)
【参考网址】
http://prfans.com/forum/viewthread.php?tid=80
http://hi.baidu.com/cat_ng/blog/item/5e59c3cea730270593457e1d.html
http://en.wikipedia.org/wiki/Generative_model
http://blog.csdn.net/yangleecool/archive/2009/04/05/4051029.aspx
==================
比较三种模型:HMMs and MRF and CRF
http://blog.sina.com.cn/s/blog_4cdaefce010082rm.html
HMMs(隐马尔科夫模型):
状态序列不能直接被观测到(hidden);
每一个观测被认为是状态序列的随机函数;
状态转移矩阵是随机函数,根据转移概率矩阵来改变状态。
HMMs与MRF的区别是只包含标号场变量,不包括观测场变量。
MRF(马尔科夫随机场)
将图像模拟成一个随机变量组成的网格。
其中的每一个变量具有明确的对由其自身之外的随机变量组成的近邻的依赖性(马尔科夫性)。
CRF(条件随机场),又称为马尔可夫随机域
一种用于标注和切分有序数据的条件概率模型。
从形式上来说CRF可以看做是一种无向图模型,考察给定输入序列的标注序列的条件概率。
在视觉问题的应用:
HMMs:图像去噪、图像纹理分割、模糊图像复原、纹理图像检索、自动目标识别等
MRF: 图像恢复、图像分割、边缘检测、纹理分析、目标匹配和识别等
CRF: 目标检测、识别、序列图像中的目标分割
P.S.
标号场为隐随机场,它描述像素的局部相关属性,采用的模型应根据人们对图像的结构与特征的认识程度,具有相当大的灵活性。
空域标号场的先验模型主要有非因果马尔可夫模型和因果马尔可夫模型。
Monday, May 10, 2010
概率图模型一点点总结
1. MCMC (in Bayesian Network Inference)
MCMC的主要步骤:
给定一个贝叶斯网络的query,固定其中的evidence variable,对剩下的non-evidence
variable反复进行如下操作:
1. 随机初始化所有的non-evidence variables
2. 对于某个non-evidence variable,给定其markove blanket对其进行sample
这整个过程是一个markov链,每个状态都对应于query variable的一个sample。将这个过
程进行一段时间后(到达平稳分布),这些所有query variable的取样结果统计一下就可
以得到query variable的近似推理结果。
关于平稳分布(stationary distribution):
平稳分布要求满足detailed balance的条件(比平稳分布要更强),即P(X)q(X->X')=P(X')
q(X'->X)。
为了满足detailed balance条件,考虑一个markov chain,其中每个variable的值都是在
给定当钱状态中“所有”其它变量的当前值的情况下进行sample得到的;在贝叶斯网中,这
个条件可以放松到这个variable的markov blanket(在贝叶斯网中,对于一个变量X,X与
其它变量在给定其markov blanket的情况下条件独立)。另外为了处理markov chain的状
态转移,我们可以使用Gibbs Sampling,这可以看成是MCMC的一种特殊情况。
MCMC可以看成是Direct Sampling和Rejection Sampling等近似推理的改进。主要原因是贝
叶斯网络中进行exact inference的计算复杂度代价很高(尤其是当网络结构很复杂的时候
),近似推理可以降低开销并获得很好的效果。
2. Bayesian Network
贝叶斯网是基于贝叶斯规则的一种网络结构(有向无环图),是概率图模型的一种形式。
图的一个节点表示一个状态,图的一条边表示一个因果关系。每一个状态对应一个CPT(条
件概率表),可以用来在贝叶斯网络中进行概率推理。一般来说,条件概率表相对而言都
不大,比联合概率的表示形式要简洁很多,而且一个贝叶斯网可以表达任何一种belief
state,因此贝叶斯网络可以有效地表达很复杂的causal relationship。
上学期学过的概率推理方法有:Variable Elimination和Monte Carlo Sampling以及
likelihood weighting。
3. Stereo Matching with Belief Propagation
这篇文章主要内容有三点:一是利用MRF对Stereo Matching问题建模,二是采用Belief
Propagation对构建好的MRF模型进行概率推理,三是在此基础上增加更多的特征以提高效
果。
MRF也是概率图模型的一种,很适合用于对spatial Constraint进行建模。Markov随机场与
Gibbs Field是等价的,密度P(X) = (1/Z)*exp(-H(X)),Z是一个normalizer,H(X)是
energy function。根据MRF的Markov性质,一个site只和周围临近neighbor相关,我们可
以得到P(X(i)=Y(i)|X(s\i)=x(s\i))=(1/Z(i))exp(-H(y(i)x(s\i)))。当I比较小的时候,
由于X仅在I上进行取值,因此可在合理的时间开销范围内进行求解Z(i)。
在这篇文章中,MRF模型的目的是估算出给定图像以后其真实结构的条件概率。在进行概率
推理的时候,可以采用MCMC的方法,但是本文采用的是Belief Propagation,原因是MCMC
方法的计算开销较大。
Belief Propagation是贝叶斯网中的一种近似推理方法(存在loop的情况下需要迭代)。
BP方法分为Sum Product和Max Product两种,本文采用的是第二种,类似Viterbi算法。
最后,这个MRF模型以constraint的形式综合了其它的特征以提高性能
文章的问题是无法保证得到全局最优解;或许Hidden CRF的效果更好些?不知是否可行?
因为CRF是对序列标注问题的建模,是不是也可以用到这个问题里?它也可以包括进去隐藏
变量(HCRF),CRF得到是全局最优解。
4. Stereo Matching with Color-Weighted Correlation, Hierarchical Belief
Propagation and Occlusion Handling
这篇文章是一种global matching stereo model,主要在于:
(1) 在计算matching cost的时候,采用color weighted correlation;而前一篇文章使用
的是Birchfield and Tomasi像素差进行计算。这样的好处是算法对occlusion boundary不
那么敏感。
(2) Hierarchical Belief Propagation.
(3) Pixel Classification. 这应该是个标记(label)问题
(4) 利用绝对误差来反复迭代优化最后的结果。
MCMC的主要步骤:
给定一个贝叶斯网络的query,固定其中的evidence variable,对剩下的non-evidence
variable反复进行如下操作:
1. 随机初始化所有的non-evidence variables
2. 对于某个non-evidence variable,给定其markove blanket对其进行sample
这整个过程是一个markov链,每个状态都对应于query variable的一个sample。将这个过
程进行一段时间后(到达平稳分布),这些所有query variable的取样结果统计一下就可
以得到query variable的近似推理结果。
关于平稳分布(stationary distribution):
平稳分布要求满足detailed balance的条件(比平稳分布要更强),即P(X)q(X->X')=P(X')
q(X'->X)。
为了满足detailed balance条件,考虑一个markov chain,其中每个variable的值都是在
给定当钱状态中“所有”其它变量的当前值的情况下进行sample得到的;在贝叶斯网中,这
个条件可以放松到这个variable的markov blanket(在贝叶斯网中,对于一个变量X,X与
其它变量在给定其markov blanket的情况下条件独立)。另外为了处理markov chain的状
态转移,我们可以使用Gibbs Sampling,这可以看成是MCMC的一种特殊情况。
MCMC可以看成是Direct Sampling和Rejection Sampling等近似推理的改进。主要原因是贝
叶斯网络中进行exact inference的计算复杂度代价很高(尤其是当网络结构很复杂的时候
),近似推理可以降低开销并获得很好的效果。
2. Bayesian Network
贝叶斯网是基于贝叶斯规则的一种网络结构(有向无环图),是概率图模型的一种形式。
图的一个节点表示一个状态,图的一条边表示一个因果关系。每一个状态对应一个CPT(条
件概率表),可以用来在贝叶斯网络中进行概率推理。一般来说,条件概率表相对而言都
不大,比联合概率的表示形式要简洁很多,而且一个贝叶斯网可以表达任何一种belief
state,因此贝叶斯网络可以有效地表达很复杂的causal relationship。
上学期学过的概率推理方法有:Variable Elimination和Monte Carlo Sampling以及
likelihood weighting。
3. Stereo Matching with Belief Propagation
这篇文章主要内容有三点:一是利用MRF对Stereo Matching问题建模,二是采用Belief
Propagation对构建好的MRF模型进行概率推理,三是在此基础上增加更多的特征以提高效
果。
MRF也是概率图模型的一种,很适合用于对spatial Constraint进行建模。Markov随机场与
Gibbs Field是等价的,密度P(X) = (1/Z)*exp(-H(X)),Z是一个normalizer,H(X)是
energy function。根据MRF的Markov性质,一个site只和周围临近neighbor相关,我们可
以得到P(X(i)=Y(i)|X(s\i)=x(s\i))=(1/Z(i))exp(-H(y(i)x(s\i)))。当I比较小的时候,
由于X仅在I上进行取值,因此可在合理的时间开销范围内进行求解Z(i)。
在这篇文章中,MRF模型的目的是估算出给定图像以后其真实结构的条件概率。在进行概率
推理的时候,可以采用MCMC的方法,但是本文采用的是Belief Propagation,原因是MCMC
方法的计算开销较大。
Belief Propagation是贝叶斯网中的一种近似推理方法(存在loop的情况下需要迭代)。
BP方法分为Sum Product和Max Product两种,本文采用的是第二种,类似Viterbi算法。
最后,这个MRF模型以constraint的形式综合了其它的特征以提高性能
文章的问题是无法保证得到全局最优解;或许Hidden CRF的效果更好些?不知是否可行?
因为CRF是对序列标注问题的建模,是不是也可以用到这个问题里?它也可以包括进去隐藏
变量(HCRF),CRF得到是全局最优解。
4. Stereo Matching with Color-Weighted Correlation, Hierarchical Belief
Propagation and Occlusion Handling
这篇文章是一种global matching stereo model,主要在于:
(1) 在计算matching cost的时候,采用color weighted correlation;而前一篇文章使用
的是Birchfield and Tomasi像素差进行计算。这样的好处是算法对occlusion boundary不
那么敏感。
(2) Hierarchical Belief Propagation.
(3) Pixel Classification. 这应该是个标记(label)问题
(4) 利用绝对误差来反复迭代优化最后的结果。
Sunday, May 9, 2010
月份与花语
正月腊梅斗寒霜, 腊梅花语:独特的美丽
二月茶花白如雪, 茶花的花语是理想和可爱
三月兰花翠中立, 兰花花语富贵
四月桃花粉里白, 桃花(PeachBlossom)花语:爱情俘虏
五月玫瑰红似为, 红玫瑰花语---热恋 、热情 粉玫瑰花语---初恋
六月水栀清香撒, 栀子的花语是永恒的爱,一生的守侯与喜悦
七月荷花粉如霞, 荷花 —— 无邪、得不到的爱
八月茉莉遍地开, 茉莉:花语:你属于我、幸福、亲切、芬芳。
九月桂花香万里, 桂花的花语:永伴佳人,香满天下,誉满天下,是崇高美好的,吉祥的
十月菊花绽笑脸, 菊花花语 菊花:清净、高洁、我爱你、真情
冬月芙蓉寒中立, 芙蓉花语:脱俗持久,恩爱关怀
腊月水仙水上站, 水仙的花语:只爱自己的人
二月茶花白如雪, 茶花的花语是理想和可爱
三月兰花翠中立, 兰花花语富贵
四月桃花粉里白, 桃花(PeachBlossom)花语:爱情俘虏
五月玫瑰红似为, 红玫瑰花语---热恋 、热情 粉玫瑰花语---初恋
六月水栀清香撒, 栀子的花语是永恒的爱,一生的守侯与喜悦
七月荷花粉如霞, 荷花 —— 无邪、得不到的爱
八月茉莉遍地开, 茉莉:花语:你属于我、幸福、亲切、芬芳。
九月桂花香万里, 桂花的花语:永伴佳人,香满天下,誉满天下,是崇高美好的,吉祥的
十月菊花绽笑脸, 菊花花语 菊花:清净、高洁、我爱你、真情
冬月芙蓉寒中立, 芙蓉花语:脱俗持久,恩爱关怀
腊月水仙水上站, 水仙的花语:只爱自己的人
Saturday, May 8, 2010
福泽谕吉
国籍:日本
生卒年:1835—1901 出生之日,恰好其父亲福泽百助买到一部渴求已久的汉籍《上谕条例》,且是中国原版,晚上儿子降生,双喜临门,遂给儿子取名“谕吉”。
日文名:福沢谕吉
罗马字注音:fukuzawa yukichi
讳范,字子囲,雅号雪池、三十一谷人
社会职业:近代日本最著名的启蒙思想界、教育家,终生以著述、办学校、报刊为业。
家庭状况:下级士族家庭,父亲为汉学者。家中一兄三姊,福泽排行第五。生后一年半,父亲去世。
(一)以言论震撼社会的知识人
每个变革的时代,都有理论上的代言人。在日本从传统向近代转变过程中,一唱百和、以舆论摇动社会,著作一出则洛阳纸贵风靡天下者,唯有福泽谕吉。
福泽谕吉,日本天保五年十二月十二日(公元1835年1月10日)出生于大阪。约70年前,瓦特发明蒸汽机,标志人类文明进入一个新时代;整70年后,日本打败俄国,标志西方势力一统天下的状态被打破,又是一个划时代的事件。
福泽谕吉的父亲福泽百助,为九州丰前中津藩(今大分县西北部)禄米13石的下级士族,身份刚好可以按规定仪式谒见藩主。母亲是同藩士族桥本滨右卫门的长女。福泽百助是个儒学者,擅长经学诗文,以读书治学为理想,长期在中津藩设于大阪的货栈值勤管理粮食。夫妇生活于大阪,生育了5个子女。福泽谕吉为家中末子,出生一年半后父亲死,母亲率子女返回家乡中津。青少年时代生活贫困,为助家计打零工,在家乡体验了下级士族的痛苦,深恨身份等级制度,孕育了他后来成为反封建启蒙思想家的基础。近代开国以前,以中国宋代朱熹学说为根本的儒学是日本的主流意识形态,一般人家教育儿童都用四书五经。福泽谕吉接受的家庭教育也是儒教主义的,鄙视经商牟利、禁止看戏娱乐。十四五岁开始学习中国古典,《论语》、《孟子》自然不用说,对于《诗经》、《书经》也学得较深入,还跟先生读《蒙求》、《世说新语》、《战国策》、《老子》、《庄子》等书。离开学校后自学历史,读过《史记》、《汉书》、《后汉书》、《晋书》、《五代史》、《元明史略》等。特别喜欢《左传》,熟读十一遍。不但读书,少年福泽也爱手工艺,自己动手裱糊拉窗、做木屐、加工刀剑、修房屋等。青少年时代的福泽谕吉就表现出特立独行、不从流俗的性格。
1853年美国海军舰队闯入日本之事,不但给政府带来巨大恐慌,而且迅速传遍全国穷乡僻壤,人们议论纷纷,到处都在谈论炮术。20岁的青年福泽不满足于家乡中津的偏僻,渴望去外面的世界学习文才武艺。为了利用外文原著学习炮术,在长兄的建议和带领下,1854年福泽谕吉来到长崎,寄居于光永寺,开始学习荷兰语。当时的日本还在闭关锁国的德川幕府时代,与海外的交流仅限荷兰、中国商人来往日本贩卖货物,当时所谓外文就是指荷兰文。长崎游学期间生活困苦,既做过炮术家的食客,也做过和尚的仆从,节日时挨家逐户念经乞讨等事。1855年又入大阪的绪方洪庵的医学塾,努力于兰学(荷兰语言学术)。1856年长兄去世更使福泽家倾家荡产,一贫如洗。物质生活的困窘未曾阻碍福泽求学的热情,在绪方塾的学习夜以继日,时常通宵达旦,睡眠从不用枕头。学习内容是物理和医学。几十位学生围绕不足十部原文书,独自钻研和相互讨论。同时热心于实验,成功尝试在铁上镀锡、制作碘、氨、硫酸等,认识到儒学的空疏无用。1858年福泽谕吉至江户(今东京),在筑地铁炮洲的奥平家邸内开设家塾,讲兰学。正值日本刚与西方五国签订通商条约后不久,东京附近的通商口岸横滨出现了洋行,福泽谕吉开始自学英语。
虽然自1854年到长崎学习炮术开始就接触西方学术,但真正给福泽谕吉一生思想带来巨大冲击的,是访问美国、欧洲对于西方世界的观察体验。第一次是1860年2月至6月间以军舰奉行(海军司令)随员的身份,搭乘“咸临丸”横渡太平洋赴美。那是日本人1853年第一次看到轮船、1855年开始跟长崎荷兰人学习航海术后,首次独力驾驶蒸汽船横渡太平洋。在美国的所见所闻无不新鲜,精神受到极大刺激:不但第一次看到马车、电报,看到一个财富充溢的世界,而且体验了美国人的热情大方,男女平等、官民平等。福泽谕吉自述“出国之前,我们这些自以为是天下无可伦比的豪爽的书生总是目中无人,不畏一切。然而刚到美国就变得像新娘子一样地渺小了,连自己都觉得可笑。”第二次是1862年1月至1863年1月间,作为幕府派遣欧使节团的翻译方(口译)赴欧洲,周游法、英、荷、德、俄、西班牙、葡萄牙等国。第三次是1867年2月至7月间为购买军舰事,随幕府的军舰接受委员长小野友五郎一行再次赴美。美国、欧洲的游历使福泽看到公私各种工厂、银行、公司、寺院、学校、俱乐部等、医院,赴宴会、看歌舞,参观议院、选举等等,到处受到热情招待,亲身体验到外国人并不都是恶魔,也有光明正大道德高尚的好人。他深感盲目排外的攘夷论的愚昧,决心在日本大力提倡学习西洋,使日本成为欧美那样文明富强的国家。
在幕末“尊王攘夷”风潮中,攻击外国人被视作英雄行为,攘夷派打砸洋行、刺杀洋人以及本国主持外交的大臣,连学习外语的洋学者也不放过。自长崎、大阪游学开始福泽谕吉就醉心于西洋学术,但是无法公开表达自己的观点。1859年开始攘夷论兴盛起来后,打着洋伞走在街上就会招致杀身之祸。福泽谕吉对于社会事务噤口不言,埋头翻译、介绍西洋事情,一边教授英语,在担心恐惧中度过岁月。直至1873年前后的十多年期间,福泽谕吉夜间从来不敢出门,白天外出也用化名,数次险遭暗杀。尤其在政权交替时期,全社会都津津乐道政治,福泽谕吉置身事外。1868年明治新政府成立后,大力起用洋学者,多次请福泽谕吉出仕,福泽固辞不就而专心于教育和著述。他厌恶官吏们虚张声势媚上欺下的作风,虚伪的忠臣义士,认为只有国民去掉喜欢依附的奴性而具备独立心,国家才能够独立。他立志以身作则,只管做好自己本分之事。但他决非孤僻的隐士,而以自己的方式积极参与着社会活动。福泽谕吉毕生著书、办学校、办报刊,主要以笔、舌影响社会,以教化国民为职责。在日本19世纪后半期封建社会崩溃、近代社会诞生的历史剧变时代,与大久保利通、伊藤博文等人以冲锋陷阵、掌握政权来实现理想不同,福泽谕吉在民间以知识人角色,通过舆论影响社会,为日本走向文明开化而摇旗呐喊,树立了舆论领袖的的地位。1860年至1867年间在幕府外交部门做英文翻译外,终生在野。1868年4月创办私立学校庆应义塾,次年加入书籍批发业公会,经营出版业。1873年与加藤弘之、津田真道等人创办学术团体“明六社”,次年开始发行刊物《明六杂志》,组织演说会、发表论文,从事思想启蒙,提倡文明开化。1878年12月被芝区选为东京府会议员,1879年1月15日东京学士院成立,被选为第一任会长。1880年1月25日创办“交询社”,1882年3月1日创刊《时事新报》,直至1901年2月3日因脑溢血而死,始终作为知识人经营自己的事业。
福泽谕吉涉历多种学问又有广泛的游历体验,善于把自己观察思考所得以雅俗共赏的方式表达,因而他的一些编译著述、观点受到朝野广泛重视。在明治初期政府领导急欲改革而茫然无绪之际,福泽谕吉的《西洋事情》被权要置诸座右作为决策蓝本;1870年代陆续发表《劝学》、《文明论概略》等著作,空前畅销而且被选为学校教科书,流传至城乡各地。明治维新中,常受政府权要的顾问咨询,成为改革大纲的幕后决策者之一。《劝学》作为学校制度初建后的启蒙教材,对国民精神近代化产生了重要影响。1879年在《报知新闻》上提倡召开国会,两三个月间迅速激起全国舆论。他创办的《时事新报》,是官府和政党报纸之外民间独立舆论的代表。甲午战争期间带头捐资掀起国民支援战争的热潮。在知识新陈代谢、是猫是狗都以贩卖西洋学问为时髦的明治初期,福泽谕吉的观点被认为学术性最强。同时代人评论云:“(福泽)虽未尝膺台阁重权,然学堂、著书、新报之三大机关,莫不操纵如意。其对于朝野之势力,时或视当路大政治家,迥胜数筹云。”因此成为近代日本最著名的启蒙思想家、教育家,被称为“日本文明之父”、“日本的伏尔泰” 。1900年宫内省拨赐内帑5万日元,奖励其对于教育的功勋。他逝世后,众议院一致决议表示哀悼。
生卒年:1835—1901 出生之日,恰好其父亲福泽百助买到一部渴求已久的汉籍《上谕条例》,且是中国原版,晚上儿子降生,双喜临门,遂给儿子取名“谕吉”。
日文名:福沢谕吉
罗马字注音:fukuzawa yukichi
讳范,字子囲,雅号雪池、三十一谷人
社会职业:近代日本最著名的启蒙思想界、教育家,终生以著述、办学校、报刊为业。
家庭状况:下级士族家庭,父亲为汉学者。家中一兄三姊,福泽排行第五。生后一年半,父亲去世。
(一)以言论震撼社会的知识人
每个变革的时代,都有理论上的代言人。在日本从传统向近代转变过程中,一唱百和、以舆论摇动社会,著作一出则洛阳纸贵风靡天下者,唯有福泽谕吉。
福泽谕吉,日本天保五年十二月十二日(公元1835年1月10日)出生于大阪。约70年前,瓦特发明蒸汽机,标志人类文明进入一个新时代;整70年后,日本打败俄国,标志西方势力一统天下的状态被打破,又是一个划时代的事件。
福泽谕吉的父亲福泽百助,为九州丰前中津藩(今大分县西北部)禄米13石的下级士族,身份刚好可以按规定仪式谒见藩主。母亲是同藩士族桥本滨右卫门的长女。福泽百助是个儒学者,擅长经学诗文,以读书治学为理想,长期在中津藩设于大阪的货栈值勤管理粮食。夫妇生活于大阪,生育了5个子女。福泽谕吉为家中末子,出生一年半后父亲死,母亲率子女返回家乡中津。青少年时代生活贫困,为助家计打零工,在家乡体验了下级士族的痛苦,深恨身份等级制度,孕育了他后来成为反封建启蒙思想家的基础。近代开国以前,以中国宋代朱熹学说为根本的儒学是日本的主流意识形态,一般人家教育儿童都用四书五经。福泽谕吉接受的家庭教育也是儒教主义的,鄙视经商牟利、禁止看戏娱乐。十四五岁开始学习中国古典,《论语》、《孟子》自然不用说,对于《诗经》、《书经》也学得较深入,还跟先生读《蒙求》、《世说新语》、《战国策》、《老子》、《庄子》等书。离开学校后自学历史,读过《史记》、《汉书》、《后汉书》、《晋书》、《五代史》、《元明史略》等。特别喜欢《左传》,熟读十一遍。不但读书,少年福泽也爱手工艺,自己动手裱糊拉窗、做木屐、加工刀剑、修房屋等。青少年时代的福泽谕吉就表现出特立独行、不从流俗的性格。
1853年美国海军舰队闯入日本之事,不但给政府带来巨大恐慌,而且迅速传遍全国穷乡僻壤,人们议论纷纷,到处都在谈论炮术。20岁的青年福泽不满足于家乡中津的偏僻,渴望去外面的世界学习文才武艺。为了利用外文原著学习炮术,在长兄的建议和带领下,1854年福泽谕吉来到长崎,寄居于光永寺,开始学习荷兰语。当时的日本还在闭关锁国的德川幕府时代,与海外的交流仅限荷兰、中国商人来往日本贩卖货物,当时所谓外文就是指荷兰文。长崎游学期间生活困苦,既做过炮术家的食客,也做过和尚的仆从,节日时挨家逐户念经乞讨等事。1855年又入大阪的绪方洪庵的医学塾,努力于兰学(荷兰语言学术)。1856年长兄去世更使福泽家倾家荡产,一贫如洗。物质生活的困窘未曾阻碍福泽求学的热情,在绪方塾的学习夜以继日,时常通宵达旦,睡眠从不用枕头。学习内容是物理和医学。几十位学生围绕不足十部原文书,独自钻研和相互讨论。同时热心于实验,成功尝试在铁上镀锡、制作碘、氨、硫酸等,认识到儒学的空疏无用。1858年福泽谕吉至江户(今东京),在筑地铁炮洲的奥平家邸内开设家塾,讲兰学。正值日本刚与西方五国签订通商条约后不久,东京附近的通商口岸横滨出现了洋行,福泽谕吉开始自学英语。
虽然自1854年到长崎学习炮术开始就接触西方学术,但真正给福泽谕吉一生思想带来巨大冲击的,是访问美国、欧洲对于西方世界的观察体验。第一次是1860年2月至6月间以军舰奉行(海军司令)随员的身份,搭乘“咸临丸”横渡太平洋赴美。那是日本人1853年第一次看到轮船、1855年开始跟长崎荷兰人学习航海术后,首次独力驾驶蒸汽船横渡太平洋。在美国的所见所闻无不新鲜,精神受到极大刺激:不但第一次看到马车、电报,看到一个财富充溢的世界,而且体验了美国人的热情大方,男女平等、官民平等。福泽谕吉自述“出国之前,我们这些自以为是天下无可伦比的豪爽的书生总是目中无人,不畏一切。然而刚到美国就变得像新娘子一样地渺小了,连自己都觉得可笑。”第二次是1862年1月至1863年1月间,作为幕府派遣欧使节团的翻译方(口译)赴欧洲,周游法、英、荷、德、俄、西班牙、葡萄牙等国。第三次是1867年2月至7月间为购买军舰事,随幕府的军舰接受委员长小野友五郎一行再次赴美。美国、欧洲的游历使福泽看到公私各种工厂、银行、公司、寺院、学校、俱乐部等、医院,赴宴会、看歌舞,参观议院、选举等等,到处受到热情招待,亲身体验到外国人并不都是恶魔,也有光明正大道德高尚的好人。他深感盲目排外的攘夷论的愚昧,决心在日本大力提倡学习西洋,使日本成为欧美那样文明富强的国家。
在幕末“尊王攘夷”风潮中,攻击外国人被视作英雄行为,攘夷派打砸洋行、刺杀洋人以及本国主持外交的大臣,连学习外语的洋学者也不放过。自长崎、大阪游学开始福泽谕吉就醉心于西洋学术,但是无法公开表达自己的观点。1859年开始攘夷论兴盛起来后,打着洋伞走在街上就会招致杀身之祸。福泽谕吉对于社会事务噤口不言,埋头翻译、介绍西洋事情,一边教授英语,在担心恐惧中度过岁月。直至1873年前后的十多年期间,福泽谕吉夜间从来不敢出门,白天外出也用化名,数次险遭暗杀。尤其在政权交替时期,全社会都津津乐道政治,福泽谕吉置身事外。1868年明治新政府成立后,大力起用洋学者,多次请福泽谕吉出仕,福泽固辞不就而专心于教育和著述。他厌恶官吏们虚张声势媚上欺下的作风,虚伪的忠臣义士,认为只有国民去掉喜欢依附的奴性而具备独立心,国家才能够独立。他立志以身作则,只管做好自己本分之事。但他决非孤僻的隐士,而以自己的方式积极参与着社会活动。福泽谕吉毕生著书、办学校、办报刊,主要以笔、舌影响社会,以教化国民为职责。在日本19世纪后半期封建社会崩溃、近代社会诞生的历史剧变时代,与大久保利通、伊藤博文等人以冲锋陷阵、掌握政权来实现理想不同,福泽谕吉在民间以知识人角色,通过舆论影响社会,为日本走向文明开化而摇旗呐喊,树立了舆论领袖的的地位。1860年至1867年间在幕府外交部门做英文翻译外,终生在野。1868年4月创办私立学校庆应义塾,次年加入书籍批发业公会,经营出版业。1873年与加藤弘之、津田真道等人创办学术团体“明六社”,次年开始发行刊物《明六杂志》,组织演说会、发表论文,从事思想启蒙,提倡文明开化。1878年12月被芝区选为东京府会议员,1879年1月15日东京学士院成立,被选为第一任会长。1880年1月25日创办“交询社”,1882年3月1日创刊《时事新报》,直至1901年2月3日因脑溢血而死,始终作为知识人经营自己的事业。
福泽谕吉涉历多种学问又有广泛的游历体验,善于把自己观察思考所得以雅俗共赏的方式表达,因而他的一些编译著述、观点受到朝野广泛重视。在明治初期政府领导急欲改革而茫然无绪之际,福泽谕吉的《西洋事情》被权要置诸座右作为决策蓝本;1870年代陆续发表《劝学》、《文明论概略》等著作,空前畅销而且被选为学校教科书,流传至城乡各地。明治维新中,常受政府权要的顾问咨询,成为改革大纲的幕后决策者之一。《劝学》作为学校制度初建后的启蒙教材,对国民精神近代化产生了重要影响。1879年在《报知新闻》上提倡召开国会,两三个月间迅速激起全国舆论。他创办的《时事新报》,是官府和政党报纸之外民间独立舆论的代表。甲午战争期间带头捐资掀起国民支援战争的热潮。在知识新陈代谢、是猫是狗都以贩卖西洋学问为时髦的明治初期,福泽谕吉的观点被认为学术性最强。同时代人评论云:“(福泽)虽未尝膺台阁重权,然学堂、著书、新报之三大机关,莫不操纵如意。其对于朝野之势力,时或视当路大政治家,迥胜数筹云。”因此成为近代日本最著名的启蒙思想家、教育家,被称为“日本文明之父”、“日本的伏尔泰” 。1900年宫内省拨赐内帑5万日元,奖励其对于教育的功勋。他逝世后,众议院一致决议表示哀悼。
Wednesday, April 28, 2010
[zz BYR] 我们手拉手赶末班车
发信人: fly1986 (小飞 ), 信区: Feeling
标 题: 我们手拉手赶末班车
发信站: 北邮人论坛 (Mon Apr 26 11:03:53 2010), 站内
周末一个聚会,晚上十点半结束,和BF赶末班车
从一号线木樨地到五号线北苑路北,
一路上一号换二号,二号换五号,终于都赶上了
我们手拉手跑着,不知道为什么感觉特别幸福
只用了四块钱,省下了近100块的打车费,
喜欢这样一起奔波的小日子
其实两个人在一起可以很简单
尽管我们现在拥有的很少,但可以手拉手一起向前冲
--------------
有时候想想,幸福真的是一种奢侈,可能这世界绝大部分人都没有办法找到两情相悦又皆大欢喜的感情吧,就像这样的,手拉手特别纯特别甜蜜的感情。。。有时候想想,可能很多人一辈子就会很平淡的过去了,只能从电影里边寻找自己年轻时候不切实际的冲动。。可是呢,可是呢,心里却总会有那么一丝残念。。
呵呵,残念,什么叫残念。。。就是一切回忆过去以后,明知不可以但却总是无时无刻幻想某一天会发生的奇迹。。。。
不知道自己会等到什么时候,也不知道自己为什么会这么执着。。。我也明白自己不怎么受待见,也知道很多地方我做的很差,甚至觉得自己一直在伤害她。。所以小半年了都一直没有联系,这样她会开心些吧,但愿
标 题: 我们手拉手赶末班车
发信站: 北邮人论坛 (Mon Apr 26 11:03:53 2010), 站内
周末一个聚会,晚上十点半结束,和BF赶末班车
从一号线木樨地到五号线北苑路北,
一路上一号换二号,二号换五号,终于都赶上了
我们手拉手跑着,不知道为什么感觉特别幸福
只用了四块钱,省下了近100块的打车费,
喜欢这样一起奔波的小日子
其实两个人在一起可以很简单
尽管我们现在拥有的很少,但可以手拉手一起向前冲
--------------
有时候想想,幸福真的是一种奢侈,可能这世界绝大部分人都没有办法找到两情相悦又皆大欢喜的感情吧,就像这样的,手拉手特别纯特别甜蜜的感情。。。有时候想想,可能很多人一辈子就会很平淡的过去了,只能从电影里边寻找自己年轻时候不切实际的冲动。。可是呢,可是呢,心里却总会有那么一丝残念。。
呵呵,残念,什么叫残念。。。就是一切回忆过去以后,明知不可以但却总是无时无刻幻想某一天会发生的奇迹。。。。
不知道自己会等到什么时候,也不知道自己为什么会这么执着。。。我也明白自己不怎么受待见,也知道很多地方我做的很差,甚至觉得自己一直在伤害她。。所以小半年了都一直没有联系,这样她会开心些吧,但愿
Friday, April 16, 2010
频率学派(Frequentist)与贝叶斯学派(Bayesian)
发信人: dychdych (sir), 信区: Statistics
标 题: Frequentist and Bayesian
发信站: Unknown Space - 未名空间 (Fri Nov 14 19:48:02 2003) WWW-POST
有人学了多年统计说不清楚频率学派与贝叶斯学派的区别,什么主观对客观啦,什么似然
函数对后验概率啦,那些都是现象,不是本质。两者本质上的区别是:频率学派把未知参
数看作普通变量,把样本看作随机变量;而贝叶斯学派把一切变量看作随机变量。
数学与统计学最大的区别在于数学研究的是变量,而统计学研究的是随机变量。对统计学
家来说,把一切变量看作随机变量是更自然的事。
如果说贝叶斯学派是纯粹的统计学家,那么频率学派就是数学统计学家,尚处在从数学向
统计学过渡的中间阶段,好比蝌蚪。既然你已经从鱼变成了青蛙,为什么还要保留尾巴呢
?
如果一切变量都是随机变量的话,那么频率学派的很多概念就失去了意义。比如无偏估计
。
若E(T)=t则说统计量T是未知参数t的unbiased estimator。如果参数t是随机变量,那个
等号就毫无意义,因为统计量T的期望E(T)是一个数量,它不可能等于一个随机变量,除
了trivial的情况下。
另外,在对置信区间的含义作解释时,也不用像频率学派那样费劲。什么未知参数是未知
而固定的值,而区间是随机区间,因为区间的端点是统计量,因而也是随机变量,每次随
着观测样本的不同,我们所得到的区间估计也不一样,当试验次数足够大时,大约有95%
的区间包含那个固定的未知参数。多么麻烦!为了能够自圆其说而绕来绕去。
历史上贝叶斯学派一直沉寂主要原因是贝叶斯学派要计算的后验概率非常烦琐,推导来推
导去,最后很多结果没有显式表示。在计算机高度发展的今天以及各种蒙特卡罗数值算法
的引入与普及,贝叶斯学派终将占据统治地位,那时的统计学将是纯粹的统计学。
发信人: yeren (野人), 信区: Statistics
标 题: Re: Frequentist and Bayesian
发信站: Unknown Space - 未名空间 (Fri Nov 14 22:32:55 2003) WWW-POST
呵呵,我不同意你的观点。
先申明我也是Bayesian(or Empirical Bayesian).
频率学派与贝叶斯学派的区别主要是是否允许先验概率分布的使用。
频率学派并不把所有参数看作普通变量(我想应该是known or unknown fixed
variable,姑且用你的名词),比如hierarchical model和random effect model。
而贝叶斯学派在先验分布中也有普通变量,比如hyperprior parameter。
你对无偏估计的论断我也不同意,因为你的定义本身不合理。如果t是随机变量,
你可以用E[T|t]=t,或者在由边际分布得到E[T]=m,一个独立于t的量。
贝叶斯的好处在于贝叶斯的推断问题相对简单,点估计,区间估计和假设检验
全部可以由后验分布得到,尤其是计算机技术的发展和MCMC方法的出现使得
非共轭后验分布的使用和计算成为可能。而且它的理论架构天然符合人渐进
的认识规律。我今天早上刚好还想到可以用“时时勤拂拭,莫使惹尘埃”来
形容贝叶斯学派,恰不恰当大家看看。
但是贝叶斯(Full Bayesian)的问题在于,无信息先验已经被证明是不存在的。所有的先
验
在参数变换后都不可避免的带有主观性。而频率学派用最大似然估计(MLE)则没有这个
问题。频率学派的困难在于如何利用前人已有经验和枢轴统计量的构造。
几十年来两个学派争论不休,都曾经相互断言对方的必将灭亡,但目前都还看不到
迹象。而这期间两者的折衷经验贝叶斯倒发展起来了。经验贝叶斯与传统贝叶斯的
不同是,它用数据来估计(marginal maximum likelihood estimator,MMLE)先验
分布中的参数。因此它为一些频率学派学者所接受。
除了贝叶斯学派和频率学派,还有似然学派。似然学派主张用MLE和LR(likelihood
ratio)
作为推断基础,废除广为使用的p-value。但是似然学派方法应用太难,好象目前看不到
什么曙光(对似然学派我也太清楚,欢迎批驳)。
总之,我觉得贝叶斯学派和频率学派的争论就好象光学波动论和粒子论的争论,也许
最后会有一个更好的框架来统一它(似然学派自认为能担此重任),希望我有生之年
能看到。
标 题: Frequentist and Bayesian
发信站: Unknown Space - 未名空间 (Fri Nov 14 19:48:02 2003) WWW-POST
有人学了多年统计说不清楚频率学派与贝叶斯学派的区别,什么主观对客观啦,什么似然
函数对后验概率啦,那些都是现象,不是本质。两者本质上的区别是:频率学派把未知参
数看作普通变量,把样本看作随机变量;而贝叶斯学派把一切变量看作随机变量。
数学与统计学最大的区别在于数学研究的是变量,而统计学研究的是随机变量。对统计学
家来说,把一切变量看作随机变量是更自然的事。
如果说贝叶斯学派是纯粹的统计学家,那么频率学派就是数学统计学家,尚处在从数学向
统计学过渡的中间阶段,好比蝌蚪。既然你已经从鱼变成了青蛙,为什么还要保留尾巴呢
?
如果一切变量都是随机变量的话,那么频率学派的很多概念就失去了意义。比如无偏估计
。
若E(T)=t则说统计量T是未知参数t的unbiased estimator。如果参数t是随机变量,那个
等号就毫无意义,因为统计量T的期望E(T)是一个数量,它不可能等于一个随机变量,除
了trivial的情况下。
另外,在对置信区间的含义作解释时,也不用像频率学派那样费劲。什么未知参数是未知
而固定的值,而区间是随机区间,因为区间的端点是统计量,因而也是随机变量,每次随
着观测样本的不同,我们所得到的区间估计也不一样,当试验次数足够大时,大约有95%
的区间包含那个固定的未知参数。多么麻烦!为了能够自圆其说而绕来绕去。
历史上贝叶斯学派一直沉寂主要原因是贝叶斯学派要计算的后验概率非常烦琐,推导来推
导去,最后很多结果没有显式表示。在计算机高度发展的今天以及各种蒙特卡罗数值算法
的引入与普及,贝叶斯学派终将占据统治地位,那时的统计学将是纯粹的统计学。
发信人: yeren (野人), 信区: Statistics
标 题: Re: Frequentist and Bayesian
发信站: Unknown Space - 未名空间 (Fri Nov 14 22:32:55 2003) WWW-POST
呵呵,我不同意你的观点。
先申明我也是Bayesian(or Empirical Bayesian).
频率学派与贝叶斯学派的区别主要是是否允许先验概率分布的使用。
频率学派并不把所有参数看作普通变量(我想应该是known or unknown fixed
variable,姑且用你的名词),比如hierarchical model和random effect model。
而贝叶斯学派在先验分布中也有普通变量,比如hyperprior parameter。
你对无偏估计的论断我也不同意,因为你的定义本身不合理。如果t是随机变量,
你可以用E[T|t]=t,或者在由边际分布得到E[T]=m,一个独立于t的量。
贝叶斯的好处在于贝叶斯的推断问题相对简单,点估计,区间估计和假设检验
全部可以由后验分布得到,尤其是计算机技术的发展和MCMC方法的出现使得
非共轭后验分布的使用和计算成为可能。而且它的理论架构天然符合人渐进
的认识规律。我今天早上刚好还想到可以用“时时勤拂拭,莫使惹尘埃”来
形容贝叶斯学派,恰不恰当大家看看。
但是贝叶斯(Full Bayesian)的问题在于,无信息先验已经被证明是不存在的。所有的先
验
在参数变换后都不可避免的带有主观性。而频率学派用最大似然估计(MLE)则没有这个
问题。频率学派的困难在于如何利用前人已有经验和枢轴统计量的构造。
几十年来两个学派争论不休,都曾经相互断言对方的必将灭亡,但目前都还看不到
迹象。而这期间两者的折衷经验贝叶斯倒发展起来了。经验贝叶斯与传统贝叶斯的
不同是,它用数据来估计(marginal maximum likelihood estimator,MMLE)先验
分布中的参数。因此它为一些频率学派学者所接受。
除了贝叶斯学派和频率学派,还有似然学派。似然学派主张用MLE和LR(likelihood
ratio)
作为推断基础,废除广为使用的p-value。但是似然学派方法应用太难,好象目前看不到
什么曙光(对似然学派我也太清楚,欢迎批驳)。
总之,我觉得贝叶斯学派和频率学派的争论就好象光学波动论和粒子论的争论,也许
最后会有一个更好的框架来统一它(似然学派自认为能担此重任),希望我有生之年
能看到。
Thursday, March 25, 2010
Create User in MySQL
mysql> create user 'username' identified by 'password';
mysql> grant all privileges on 'dbname' to 'username'@localhost identified by 'password' with grant option;
mysql> grant select, insert, update, delete, create, drop
-> on db.'dbname'
-> to 'username'@localhost
-> identified by 'password';
mysql> grant all privileges on 'dbname' to 'username'@localhost identified by 'password' with grant option;
mysql> grant select, insert, update, delete, create, drop
-> on db.'dbname'
-> to 'username'@localhost
-> identified by 'password';
Wednesday, March 24, 2010
[Wamp] Fatal error: Maximum execution time of 300 seconds exceeded
This is caused by the default configuration of wamp server. To modify this, you need to find libraries/config.default.php. You can see all default configurations here. Find the one you need to change; in this case, it should be:
$cfg['ExecTimeLimit'] integer [number of seconds]
Function of the value of this variable:
Set the number of seconds a script is allowed to run. If seconds is set to zero, no time limit is imposed.This setting is used while importing/exporting dump files but has no effect when PHP is running in safe mode.
$cfg['ExecTimeLimit'] integer [number of seconds]
Function of the value of this variable:
Set the number of seconds a script is allowed to run. If seconds is set to zero, no time limit is imposed.This setting is used while importing/exporting dump files but has no effect when PHP is running in safe mode.
Increase Limit on Dumpfile Size in MySQL
If you are using wamp server, please do the following:
> sudo gedit /etc/php5/apache2/php.ini
Modify
a) post_max_size
b) memory_limit
c) upload_max_filesize
In an order memory_limit > post_max_size (size greater than required DB) > upload_max_filesize Restart apache.
If you are using MySQL alone, please modify your "my.ini" file. If you cannot find such a file, please make a copy of your "my-medium.cnf" file and rename it to "my.ini". You'll find "max_allowed_packet" variable. Then change its value to a larger one you need!!!
> sudo gedit /etc/php5/apache2/php.ini
Modify
a) post_max_size
b) memory_limit
c) upload_max_filesize
In an order memory_limit > post_max_size (size greater than required DB) > upload_max_filesize Restart apache.
If you are using MySQL alone, please modify your "my.ini" file. If you cannot find such a file, please make a copy of your "my-medium.cnf" file and rename it to "my.ini". You'll find "max_allowed_packet" variable. Then change its value to a larger one you need!!!
Monday, March 22, 2010
Thursday, March 18, 2010
Hadoop中Writable接口的序列化
一种常用的序列化方法如下:
public static class Key implements WritableComparable { public String id = ""; public short weight; public Key() { } public Key(String i, short j) { id = i; weight = j; } @Override public void readFields(DataInput in) throws IOException { //先写字符串的长度信息 int length = in.readInt(); byte[] buf = new byte[length]; in.readFully(buf, 0, length); //得到id号 id = new String(buf); //得到权值 weight = in.readShort(); } @Override public void write(DataOutput out) throws IOException { String str = id.toString(); int length = str.length(); byte[] buf = str.getBytes(); //先写字符串长度 //WritableUtils.writeVInt(out, length); out.writeInt(length); //再写字符串数据 out.write(buf, 0, length); //接着是权值 out.writeShort(weight); } @Override public int hashCode() { return id.hashCode(); } @Override public String toString() { return id; } @Override public boolean equals(Object right) { //只要id相等就认为两个key相等 if (right instanceof Key) { Key r = (Key) right; return r.id.equals(id); } else { return false; } } @Override public int compareTo(Key k) { System.out.println("in compareTo, key=" + k.toString()); //先比较value id int cmp = id.compareTo(k.id); if (cmp != 0) { return cmp; } //如果value id相等,再比较权值 if (weight > k.weight) return -1; else if (weight < k.weight) return 1; else return 0; } }
public static class Key implements WritableComparable
解决Hadoop中的“输出目录已存在”的问题
Hadoop中使用Map Reduce时,每次运行的输出目录必须事先未建好,导致如果想使用相同的output目录,每次运行程序之前都要先删掉之前的输出目录。其实这一操作可以嵌到代码中执行:
FileSystem fstm = FileSystem.get(conf);
Path outDir = new Path(args[2]);
fstm.delete(outDir, true);
这样即可解决问题。
FileSystem fstm = FileSystem.get(conf);
Path outDir = new Path(args[2]);
fstm.delete(outDir, true);
这样即可解决问题。
Wednesday, March 17, 2010
Linux下设置环境变量
JAVA:
$ export JAVA_HOME=/usr/java/jdk1.6.0_07
$ export PATH=$PATH:$JAVA_HOME/bin
hadoop:
First setup the HADOOP_HOME environment variable to the install directory. Then append $HADOOP_HOME/bin to your PATH environment variable. It is advisable to add these to profile setup scripts.
$ export HADOOP_HOME=/u/kduan/Desktop/hadoop-0.20.2
$ export PATH=$PATH:$HADOOP_HOME/bin
要注意的是,等号的左右不能出现空格。最好修改一下.bash_profile文件,把上述export命令添加进去,这样每次用户登录时自动执行export命令。
$ export JAVA_HOME=/usr/java/jdk1.6.0_07
$ export PATH=$PATH:$JAVA_HOME/bin
hadoop:
First setup the HADOOP_HOME environment variable to the install directory. Then append $HADOOP_HOME/bin to your PATH environment variable. It is advisable to add these to profile setup scripts.
$ export HADOOP_HOME=/u/kduan/Desktop/hadoop-0.20.2
$ export PATH=$PATH:$HADOOP_HOME/bin
要注意的是,等号的左右不能出现空格。最好修改一下.bash_profile文件,把上述export命令添加进去,这样每次用户登录时自动执行export命令。
javac -classpath 的使用
javac: 如果当前你要编译的java文件中引用了其它的类(比如说:继承),但该引用类的.class文件不在当前目录下,这种情况下就需要在javac命令后面 加上-classpath参数,通过使用以下三种类型的方法 来指导编译器在编译的时候去指定的路径下查找引用类。
(1).绝对路径:javac -classpath c:\junit3.8.1\junit.jar Xxx.java
(2).相对路径:javac -classpath ..\junit3.8.1\Junit.javr Xxx.java
(3).系统变量:javac -classpath %CLASSPATH% Xxx.java (注意:%CLASSPATH%表示使用系统变量CLASSPATH的值进行查找,这里假设Junit.jar的路径就包含在CLASSPATH系统变量中)
总结:(1).何时需要使用-classpath:当你要编译或执行的类引用了其它的类,但被引用类的.class文件不在当前目录下时,就需要通过-classpath来引入类
(2).何时需要指定路径:当你要编译的类所在的目录和你执行javac命令的目录不是同一个目录时,就需要指定源文件的路径(CLASSPATH是用来指定.class路径的,不是用来指定.java文件的路径的)
Wednesday, March 10, 2010
三种常见连续随机变量
均匀分布
x在[a,b]内的均匀分布,概率密度f(x)=1/(b-a),期望EX=(a+b)/2,方差DX=(b-a)^2/12
正态分布
概率密度f(x)=[1/(2πσ)^0.5]*e^[-(x-μ)^2/2σ^2],x∈(-∞,+∞),期望EX=μ,方差DX=σ
指数分布
概率密度f(x)=λe^(-λx),(x>0)。期望EX=1/λ,方差DX=1/λ^2
x在[a,b]内的均匀分布,概率密度f(x)=1/(b-a),期望EX=(a+b)/2,方差DX=(b-a)^2/12
正态分布
概率密度f(x)=[1/(2πσ)^0.5]*e^[-(x-μ)^2/2σ^2],x∈(-∞,+∞),期望EX=μ,方差DX=σ
指数分布
概率密度f(x)=λe^(-λx),(x>0)。期望EX=1/λ,方差DX=1/λ^2
Monday, March 8, 2010








(转)凤姐超强语录!
1.以我的智商和以我的能力的话,往前推三百年,往后推三百年,总共六百年之内不会有第二个人超过我。
2.爱因斯坦绝对没我聪明,他发明电灯的嘛!
3.必须具备国际视野,有征服世界的欲望。奥巴马才符合我的征婚标准。(谈择偶)
4.本人找伴侣,一不求帅,二不求富。
5.9岁博览群书,20岁到达顶峰,往前300年往后推300年,没有人会超过我。在智力上他们是不可能比我强的,那就在身高和外貌上弥补吧……
6.他太老了,而且身高也不够。他也不可能是北大清华,更不可能是经济学专业,我不会选他(陈坤)。
7.这个标准不高,这个标准很低。
8.看到其他女的就他妈花痴一样。(疯了!上电视说脏话)
9.过了三十岁自己滚蛋。
10.男人过了三十岁就没看点了,就人老珠黄了。
11.你给我十万。
12.吾日三省吾身(凤姐念错字了)省应该读 xǐng,她读shěng。
13.我用的是A4纸,因为A4是非常标准的纸。
14.因为上海是一个经济中心,我这个人对征服经济世界蛮有兴趣的。
15.我经常看的都是人文社会的书,例如《知音》、《故事会》。
16.我一般按长相将人分五等。我是第三等。(主持人指着她前男朋友问:他是几等)他啊,没有等(捂嘴笑)……
17.我在家乐福超市工作,世界500强。
18.世界上有一半的男人看到我就想逃跑,另一半我看到他就想逃跑。
19.我这个人有点洁癖,以前读书时衣服每天要洗,现在基本上过两三天就洗一次,洗头也这样,现在很多时间都浪费在这上面。
20.罗指着台下众人说:你们这些普通院校的,如果撇开这上面的七条,你们肯定有人会愿意娶我……
21.真的美女真多啊。我对面的一位男孩,开始很仔细的打量我,我想我应该还没有出名到他已经看过我的视频吧。有次有人对我说你上电视了,我说什么电视?人家说东方卫视啊。我打开电视,东方卫视正在播奥巴马的新闻。我觉得我和奥巴马之间还有很大的距离。做人,自知之明还是有的。
22.你看看你的身高你的长相,我觉得你配不上我,我们之间差距太大了,带回家的话,我家里的人肯定会嘲笑我的,他们会说,罗玉凤,你找的男朋友怎么这么丢脸啊,连话都不会讲,我觉得我们还是算了吧,我一定能够找到一个比你好的多的男朋友。
23.像我这样的一个人,独自在外面闯荡。很引人注目,可是自己想想。论交际,论人际关系,论工作能力。实在是不但女人,就是男人,也很难和我相比。论健康状况,却是一天不如一天的。我想我不能在这么下去了。
24.我最喜欢的诗人是顾城 顾城(强调) 你知道吧???
25.要说我写诗的风格嘛,比较像顾城,写文章嘛,人家都说我像鲁迅。
26.山东走出去的我可以考虑一下,目前还在山东工作的不予考虑。
27.凤姐:爱因斯坦宏观上不如我…… 激动网主持人:你指的宏观是? 凤姐:把全人类更上一层吧。
28.我弟弟长得很阳光帅气。 你弟弟长得和你很像? 对,很像!
30.我在上海的时候,一直会有人在我肩膀上摸一摸什么的,有目的性的佧我油。
31.(与主持人对话) —如果说他(指陈坤,凤姐的偶像之一)向你求婚了,跪在你面前了,玉凤你嫁给我吧,你会同意吗? —我不会同意的。首先他年龄三十三了,我觉得这个太老了哦。然后他身高可能应该也不足,然后他不是北大清华的,他根本就不可能是经济学专业的。
32.中国人民银行、花旗银行、渣打银行、汇丰银行、交通银行、中国人寿等金融公司驻中国区首席执行官向我表达爱意,愿意与我结婚,而本人觉得他们年老色衰,所以不愿意。
33.我的七大要求全国还能找到100个我认为不高,全国找到1个是还差一点,全国一个都找不出我认为是刚好。
34.征婚者:“你从哪里来?” 罗玉凤:“我从地球来。” 征婚者:“好巧我也是。” 35.我爱干净,比较洁癖,男朋友看到女的别他妈花痴样。
36.主持人:你觉得爱因斯坦也不及你聪明么? 罗玉凤:不及我不及我,差远了,他是一名科学家。 主持人:对,他是一名科学家,但是你知道他所知道的东西么? 罗玉凤:我不知道他知道的东西,我不能发明电灯。
37.罗玉凤在谈自己最喜欢的一首诗,是凤姐自己写的:天还没有黑,天已经黑了。
38.我平常接触的朋友多,因为我交际面广嘛。
39.凭我的智慧,我的相貌,我完全可以找一个比他(指前男友)更优秀的男朋友。
40.你去死!
41.很多人都说我漂亮。我也知道我漂亮。
42.我喜欢蓝莓的味道。蓝莓是一种优雅的水果,即使我毫无姿态地坐在路边的水泥地,拣起没有洗过的蓝莓塞进嘴里,我依然认为我是优雅的,因为优雅的蓝莓。
附:凤姐征婚标准
罗玉凤-征婚标准
本人找伴侣。一不求帅。二不求富。但求同甘苦,共患难。 本人对伴侣要求如下:[3]
第一,必须为北京大学或清华大学硕士毕业生。必须本科硕士连读,中途无跳级,不留级,不转校。在外参加工作后再回校读书者免。
第二,必须为经济学专业毕业。非经济学专业毕业则必须精通经济学。或对经济学有浓厚的兴趣。
第三,必须具备国际视野,但是无长期定居国外甚至移民的打算。
第四,身高176--183左右。长得越帅越好。
第五,无生育史。过往所有女友均无因自身而致的堕胎史。
第六,东部沿海户籍,即江,浙,沪三地户籍或广东,天津,山东。北京,东北三省,内蒙古等地户籍。西南地区即重庆。贵州。云南。西藏,湖南,湖北等地籍贯者不予考虑。
第七,年龄25--28岁左右。即06届,07届,08届,09届毕业生。有一至两年的工作经验,06级毕业生需年龄在28岁左右,09级毕业生则需聪明过人。且具备丰富的社会实践经验。就职于国家机关,国有企事业单位者不愿考虑。但就职于中石油,中石化等世界顶尖型企业或银行者又比较喜欢。现自主创业者要商榷一番了。 本人85年旧历8月初9日生。新历生日为9月23日。身高146。平时穿高跟鞋153。体重40kg.先就读于綦江师范学校获中师文凭。 后连读重庆教育学院获汉语言文学专业大专文凭。懂诗画,唱歌,弹琴,刺绣等。最擅长诗歌与散文。并精通古汉语。博览群书。较为狂妄。无堕胎史,无生育史。交过几个不了了之的男朋友。具体进展却无。主要要求:男方身家清白,聪慧过人。
罗玉凤-的号召力 “信凤姐,得自信" 广大凤姐支持者的口号,凤姐新时代女性的力量。
2.爱因斯坦绝对没我聪明,他发明电灯的嘛!
3.必须具备国际视野,有征服世界的欲望。奥巴马才符合我的征婚标准。(谈择偶)
4.本人找伴侣,一不求帅,二不求富。
5.9岁博览群书,20岁到达顶峰,往前300年往后推300年,没有人会超过我。在智力上他们是不可能比我强的,那就在身高和外貌上弥补吧……
6.他太老了,而且身高也不够。他也不可能是北大清华,更不可能是经济学专业,我不会选他(陈坤)。
7.这个标准不高,这个标准很低。
8.看到其他女的就他妈花痴一样。(疯了!上电视说脏话)
9.过了三十岁自己滚蛋。
10.男人过了三十岁就没看点了,就人老珠黄了。
11.你给我十万。
12.吾日三省吾身(凤姐念错字了)省应该读 xǐng,她读shěng。
13.我用的是A4纸,因为A4是非常标准的纸。
14.因为上海是一个经济中心,我这个人对征服经济世界蛮有兴趣的。
15.我经常看的都是人文社会的书,例如《知音》、《故事会》。
16.我一般按长相将人分五等。我是第三等。(主持人指着她前男朋友问:他是几等)他啊,没有等(捂嘴笑)……
17.我在家乐福超市工作,世界500强。
18.世界上有一半的男人看到我就想逃跑,另一半我看到他就想逃跑。
19.我这个人有点洁癖,以前读书时衣服每天要洗,现在基本上过两三天就洗一次,洗头也这样,现在很多时间都浪费在这上面。
20.罗指着台下众人说:你们这些普通院校的,如果撇开这上面的七条,你们肯定有人会愿意娶我……
21.真的美女真多啊。我对面的一位男孩,开始很仔细的打量我,我想我应该还没有出名到他已经看过我的视频吧。有次有人对我说你上电视了,我说什么电视?人家说东方卫视啊。我打开电视,东方卫视正在播奥巴马的新闻。我觉得我和奥巴马之间还有很大的距离。做人,自知之明还是有的。
22.你看看你的身高你的长相,我觉得你配不上我,我们之间差距太大了,带回家的话,我家里的人肯定会嘲笑我的,他们会说,罗玉凤,你找的男朋友怎么这么丢脸啊,连话都不会讲,我觉得我们还是算了吧,我一定能够找到一个比你好的多的男朋友。
23.像我这样的一个人,独自在外面闯荡。很引人注目,可是自己想想。论交际,论人际关系,论工作能力。实在是不但女人,就是男人,也很难和我相比。论健康状况,却是一天不如一天的。我想我不能在这么下去了。
24.我最喜欢的诗人是顾城 顾城(强调) 你知道吧???
25.要说我写诗的风格嘛,比较像顾城,写文章嘛,人家都说我像鲁迅。
26.山东走出去的我可以考虑一下,目前还在山东工作的不予考虑。
27.凤姐:爱因斯坦宏观上不如我…… 激动网主持人:你指的宏观是? 凤姐:把全人类更上一层吧。
28.我弟弟长得很阳光帅气。 你弟弟长得和你很像? 对,很像!
30.我在上海的时候,一直会有人在我肩膀上摸一摸什么的,有目的性的佧我油。
31.(与主持人对话) —如果说他(指陈坤,凤姐的偶像之一)向你求婚了,跪在你面前了,玉凤你嫁给我吧,你会同意吗? —我不会同意的。首先他年龄三十三了,我觉得这个太老了哦。然后他身高可能应该也不足,然后他不是北大清华的,他根本就不可能是经济学专业的。
32.中国人民银行、花旗银行、渣打银行、汇丰银行、交通银行、中国人寿等金融公司驻中国区首席执行官向我表达爱意,愿意与我结婚,而本人觉得他们年老色衰,所以不愿意。
33.我的七大要求全国还能找到100个我认为不高,全国找到1个是还差一点,全国一个都找不出我认为是刚好。
34.征婚者:“你从哪里来?” 罗玉凤:“我从地球来。” 征婚者:“好巧我也是。” 35.我爱干净,比较洁癖,男朋友看到女的别他妈花痴样。
36.主持人:你觉得爱因斯坦也不及你聪明么? 罗玉凤:不及我不及我,差远了,他是一名科学家。 主持人:对,他是一名科学家,但是你知道他所知道的东西么? 罗玉凤:我不知道他知道的东西,我不能发明电灯。
37.罗玉凤在谈自己最喜欢的一首诗,是凤姐自己写的:天还没有黑,天已经黑了。
38.我平常接触的朋友多,因为我交际面广嘛。
39.凭我的智慧,我的相貌,我完全可以找一个比他(指前男友)更优秀的男朋友。
40.你去死!
41.很多人都说我漂亮。我也知道我漂亮。
42.我喜欢蓝莓的味道。蓝莓是一种优雅的水果,即使我毫无姿态地坐在路边的水泥地,拣起没有洗过的蓝莓塞进嘴里,我依然认为我是优雅的,因为优雅的蓝莓。
附:凤姐征婚标准
罗玉凤-征婚标准
本人找伴侣。一不求帅。二不求富。但求同甘苦,共患难。 本人对伴侣要求如下:[3]
第一,必须为北京大学或清华大学硕士毕业生。必须本科硕士连读,中途无跳级,不留级,不转校。在外参加工作后再回校读书者免。
第二,必须为经济学专业毕业。非经济学专业毕业则必须精通经济学。或对经济学有浓厚的兴趣。
第三,必须具备国际视野,但是无长期定居国外甚至移民的打算。
第四,身高176--183左右。长得越帅越好。
第五,无生育史。过往所有女友均无因自身而致的堕胎史。
第六,东部沿海户籍,即江,浙,沪三地户籍或广东,天津,山东。北京,东北三省,内蒙古等地户籍。西南地区即重庆。贵州。云南。西藏,湖南,湖北等地籍贯者不予考虑。
第七,年龄25--28岁左右。即06届,07届,08届,09届毕业生。有一至两年的工作经验,06级毕业生需年龄在28岁左右,09级毕业生则需聪明过人。且具备丰富的社会实践经验。就职于国家机关,国有企事业单位者不愿考虑。但就职于中石油,中石化等世界顶尖型企业或银行者又比较喜欢。现自主创业者要商榷一番了。 本人85年旧历8月初9日生。新历生日为9月23日。身高146。平时穿高跟鞋153。体重40kg.先就读于綦江师范学校获中师文凭。 后连读重庆教育学院获汉语言文学专业大专文凭。懂诗画,唱歌,弹琴,刺绣等。最擅长诗歌与散文。并精通古汉语。博览群书。较为狂妄。无堕胎史,无生育史。交过几个不了了之的男朋友。具体进展却无。主要要求:男方身家清白,聪慧过人。
罗玉凤-的号召力 “信凤姐,得自信" 广大凤姐支持者的口号,凤姐新时代女性的力量。
Friday, March 5, 2010
关于十月围城、刘墉及其他
昨天看了一遍十月围城,总体感觉一般。作为动作片,武打场面和效果其实并不出彩,比叶问要差多了;作为剧情片,它的剧情设置得好像也不太合理。比如说重光的死,刘少白对李玉堂说过,“革命就是用我们这一辈的牺牲,来换取重光这一辈人的幸福”,而且“重光”二字的寓意不也正在此吗?可是这部电影最终选择了让重光结束了生命,莫非是一种诏白,革命的未来就是灭亡?还有阿纯,很好的一个姑娘,在这群人中我觉得其实算是有思想了,能看出她也很坚强,但是结局好像没有再现阿纯(我没记错吧?),不能不说是一个遗憾。
但是这部电影还是挺反应当时现实的,真真正正的一部《LOST》。在这一大群人中,除了孙中山自己,好像真正懂得革命的就没什么人了,每个人活得都挺迷茫。那个李玉堂,反复的说“我只是个生意人”、“我只出钱不出力”,虽然一度组织大家高声呐喊保护孙先生,但是当发现刘少白没死,就立即退缩了。他骨子里根本不明白革命的意义,大概是许多当时商人的写照吧。再说重光,就是一个热血青年,受刘少白的影响一心向往“革命”,但是给人的感觉却是可怜和可惜。其实有很多牺牲都是可以避免的,但是是需要真正的智慧的。剩下来的阿四,臭豆腐,方红等等人,其实根本就跟革命不搭边儿么,这样的牺牲,说句不好听的,属于“死都不知道怎么死”的那种,难道不是一种悲哀?
演员演技都还不错,特别是李宇春和巴特尔,一个卖唱的,一个卖艺的,能有这样的表现已经很赞了,嘿嘿。谢霆锋演得也真不错,感觉他演技越来越成熟了。不过最让我震撼的应该是胡军了,演这样一个没有脑子反面人物,冷冷的眼神,麻木的内心,表现力超强的。甄子丹的武打戏是这部电影里的一个亮点,不过没有延续叶师傅的风格,有点儿可惜。
不过好像本人并不是很喜欢看这种的电影,最好是文艺一点儿的,然后又能告诉人一些道理的那种,嘿嘿。特别不喜欢阿凡达一类的电影,几乎只有感官的冲击和刺激,却缺少心灵的震撼。
哦,还有啊,最近不好意思确实很闲,读了不少刘墉的文章,总觉得如果要用一个字来形容刘墉的文字的话,其实就是一个“爱”字。不是那种“无形”的大爱,而是那种无微不至的小爱。不管是对嗷嗷待哺的婴儿,对自己深爱的妻,还是对身边的一花一草,一房一木,都渗透着很细腻的感情。这也可能是因为刘墉本身就是个热爱生活的画家吧,比如看他画昙花,都是在抱着一种强烈的感情,非常之投入,非常之感人。。。再看看他写的那篇雨花石,“看到水中的雨花石映出来的人影”,简直是把一堆石头写活了,每一块石头都好像在诉说自己的故事一样。他深爱这石头,也深爱着孩子,当孩子们看到这么漂亮的雨花石的时候,他毫不犹豫的把他们都送给了孩子们。仔细想想,这样的生活态度不正是我想要的么。。。
还有还有,不想再自欺欺人了。与其说伪装是一种力量,不如说它就是一针麻醉剂。人还是活得痛痛快快真真切切的更好。
但是这部电影还是挺反应当时现实的,真真正正的一部《LOST》。在这一大群人中,除了孙中山自己,好像真正懂得革命的就没什么人了,每个人活得都挺迷茫。那个李玉堂,反复的说“我只是个生意人”、“我只出钱不出力”,虽然一度组织大家高声呐喊保护孙先生,但是当发现刘少白没死,就立即退缩了。他骨子里根本不明白革命的意义,大概是许多当时商人的写照吧。再说重光,就是一个热血青年,受刘少白的影响一心向往“革命”,但是给人的感觉却是可怜和可惜。其实有很多牺牲都是可以避免的,但是是需要真正的智慧的。剩下来的阿四,臭豆腐,方红等等人,其实根本就跟革命不搭边儿么,这样的牺牲,说句不好听的,属于“死都不知道怎么死”的那种,难道不是一种悲哀?
演员演技都还不错,特别是李宇春和巴特尔,一个卖唱的,一个卖艺的,能有这样的表现已经很赞了,嘿嘿。谢霆锋演得也真不错,感觉他演技越来越成熟了。不过最让我震撼的应该是胡军了,演这样一个没有脑子反面人物,冷冷的眼神,麻木的内心,表现力超强的。甄子丹的武打戏是这部电影里的一个亮点,不过没有延续叶师傅的风格,有点儿可惜。
不过好像本人并不是很喜欢看这种的电影,最好是文艺一点儿的,然后又能告诉人一些道理的那种,嘿嘿。特别不喜欢阿凡达一类的电影,几乎只有感官的冲击和刺激,却缺少心灵的震撼。
哦,还有啊,最近不好意思确实很闲,读了不少刘墉的文章,总觉得如果要用一个字来形容刘墉的文字的话,其实就是一个“爱”字。不是那种“无形”的大爱,而是那种无微不至的小爱。不管是对嗷嗷待哺的婴儿,对自己深爱的妻,还是对身边的一花一草,一房一木,都渗透着很细腻的感情。这也可能是因为刘墉本身就是个热爱生活的画家吧,比如看他画昙花,都是在抱着一种强烈的感情,非常之投入,非常之感人。。。再看看他写的那篇雨花石,“看到水中的雨花石映出来的人影”,简直是把一堆石头写活了,每一块石头都好像在诉说自己的故事一样。他深爱这石头,也深爱着孩子,当孩子们看到这么漂亮的雨花石的时候,他毫不犹豫的把他们都送给了孩子们。仔细想想,这样的生活态度不正是我想要的么。。。
还有还有,不想再自欺欺人了。与其说伪装是一种力量,不如说它就是一针麻醉剂。人还是活得痛痛快快真真切切的更好。
Play with Nutch - System Setup in Windows Environment
1. Preparation
Software needs:
Cygwin: used to support shell commands in windows environment. Nutch does not provide separate scripts for NT cmd!! (NT cmd shell does not nest environments recursively)
Tomcat: used to provide servers!!
Nutch 1.0: latest vesion of Nutch!! After downloading, please extract nutch files under the /home/yourusername directory in Cygwin.
2. Set up environment variables for BOTH windows and Cygwin
(a) Set up the following environment variables for windows
JAVA_HOME: value = your_java_jre_location (e.g. D:\SoftWare\JAVA)
NUTCH_HOME: value = your_nutch_location (e.g. D:\SoftWare\cygwin\)
NUTCH_JAVA_HOME: same with JAVA_HOME
Then add these variables into "path".
(b) Add the following scripts into .bash_profile
PATH="/usr/local/bin:/usr/bin:/bin:$PATH:/cygdrive/d/SoftWare/JAVA";
export CLASSPATH=D:\SyftWare\cygwin\home\yourusername\nutch\lib\lucene-core-2.4.0;
export JAVA_HOME=/cygdrive/d/SoftWare/JAVA;
if [ -f ~/.bashrc ]; then . ~/.bashrc; fi
3. Test your Nutch
Create a folder "urls" in /home/yourusername/nutch/bin/; then create a text file "url.txt" in it. Write in the web address you want to crawl, e.g. http://www.iub.edu/. Don't forget the "/" at the end of the address. (This is important)
Now modify crawl-urlfilter.txt under \home\kduan\nutch\conf. Identify the following:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
Change it to:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*iub.edu/
Then modify nutch-site.xml in the same folder. The use the following scripts to override
<:property>
http.agent.name
HD nutch agent
<:property>
http.agent.version
1.0
Now you can test your crawler. Run following script:
$ nutch crawl urls -dir crawl -depth 3 -topN 50
If you are not so sure about these arguments, please just type "nutch crawl" to see the specifications!!
The crawler should be working now. You can find the crawled results in "crawl" folder that we have just speficied in our script. If want to search through the results, you can simply run:
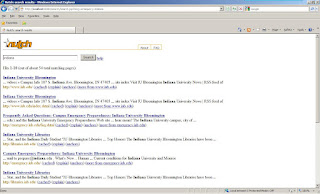
$ nutch org.apache.nutch.searcher.NutchBean indiana
where "indiana" is a keyword we are searching for, then you'll see the following :
$ nutch org.apache.nutch.searcher.NutchBean indianaTotal hits: 54 0 20100305123428/http://www.iub.edu/ ... videos ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 1 20100305123447/http://www.iub.edu/index.shtml ... videos ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 2 20100305123537/http://emergency.iub.edu/faq.shtml ... edu ) and the Indiana University Emergency Preparedness Web site ... hear mean? The Indiana University campus, city of ... 3 20100305123447/http://www.iub.edu/videos/index.shtml ... performances. Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 4 20100305123447/http://libraries.iub.edu/ ... Star, and the Indiana Daily Student "IU-Bloomington Libraries ... Top Honors The Indiana University Bloomington Libraries have been ... 5 20100305123447/http://www.iub.edu/slideshows/index.shtml ... Stories ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 6 20100305123447/http://www.iub.edu/academic/index.shtml ... departments Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... siteindex Visit IU Bloomington Indiana University News RSS feed of 7 20100305123447/http://www.iub.edu/comments/index.shtml ... here ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site indexVisit IU Bloomington Indiana University News RSS feed of 8 20100305123447/http://www.iub.edu/student/index.shtml ... consultants Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... siteindex Visit IU Bloomington Indiana University News RSS feed of 9 20100305123447/http://www.iub.edu/about/index.shtml ... Bloomington Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... siteindex Visit IU Bloomington Indiana University News RSS feed of
Total hits is the number of records found!!
4. Use Nutch on Tomcat servers
Copy nutch-1.0.war (under root folder of Nutch) to webapps under Tomcat installation folder, and rename it to search.war. Start Tomcat to let it automatically extract contents from this archive. Modify nutch-site.xml in tomcat\webapps\search\WEB-INF\classes; add the following property:
searcher.dir
D:\SoftWare\cygwin\home\kduan\nutch\bin\crawl
This is to specify the targeted search directory, i.e. where you put the crawled contents.
Special note to Chinese users.
Then modify server.xml in tomcat\conf, identify the "Connector" part and add
URIEncoding="UTF-8" useBodyEncodingForURI="true"
We use URIEncoding="UTF-8" useBodyEncodingForURI="true" here to solve Chinese character encoding problem.
Then you can restart Tomcat, then type http://localhost:8080/search to the Nutch search page. Then you have set up a search engine now!!
Here is a screenshot. Have fun!!
Software needs:
Cygwin: used to support shell commands in windows environment. Nutch does not provide separate scripts for NT cmd!! (NT cmd shell does not nest environments recursively)
Tomcat: used to provide servers!!
Nutch 1.0: latest vesion of Nutch!! After downloading, please extract nutch files under the /home/yourusername directory in Cygwin.
2. Set up environment variables for BOTH windows and Cygwin
(a) Set up the following environment variables for windows
JAVA_HOME: value = your_java_jre_location (e.g. D:\SoftWare\JAVA)
NUTCH_HOME: value = your_nutch_location (e.g. D:\SoftWare\cygwin\)
NUTCH_JAVA_HOME: same with JAVA_HOME
Then add these variables into "path".
(b) Add the following scripts into .bash_profile
PATH="/usr/local/bin:/usr/bin:/bin:$PATH:/cygdrive/d/SoftWare/JAVA";
export CLASSPATH=D:\SyftWare\cygwin\home\yourusername\nutch\lib\lucene-core-2.4.0;
export JAVA_HOME=/cygdrive/d/SoftWare/JAVA;
if [ -f ~/.bashrc ]; then . ~/.bashrc; fi
3. Test your Nutch
Create a folder "urls" in /home/yourusername/nutch/bin/; then create a text file "url.txt" in it. Write in the web address you want to crawl, e.g. http://www.iub.edu/. Don't forget the "/" at the end of the address. (This is important)
Now modify crawl-urlfilter.txt under \home\kduan\nutch\conf. Identify the following:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
Change it to:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*iub.edu/
Then modify nutch-site.xml in the same folder. The use the following scripts to override
<:property>
HD nutch agent
1.0
Now you can test your crawler. Run following script:
$ nutch crawl urls -dir crawl -depth 3 -topN 50
If you are not so sure about these arguments, please just type "nutch crawl" to see the specifications!!
The crawler should be working now. You can find the crawled results in "crawl" folder that we have just speficied in our script. If want to search through the results, you can simply run:
$ nutch org.apache.nutch.searcher.NutchBean indiana
where "indiana" is a keyword we are searching for, then you'll see the following :
$ nutch org.apache.nutch.searcher.NutchBean indianaTotal hits: 54 0 20100305123428/http://www.iub.edu/ ... videos ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 1 20100305123447/http://www.iub.edu/index.shtml ... videos ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 2 20100305123537/http://emergency.iub.edu/faq.shtml ... edu ) and the Indiana University Emergency Preparedness Web site ... hear mean? The Indiana University campus, city of ... 3 20100305123447/http://www.iub.edu/videos/index.shtml ... performances. Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 4 20100305123447/http://libraries.iub.edu/ ... Star, and the Indiana Daily Student "IU-Bloomington Libraries ... Top Honors The Indiana University Bloomington Libraries have been ... 5 20100305123447/http://www.iub.edu/slideshows/index.shtml ... Stories ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site index Visit IU Bloomington Indiana University News RSS feed of 6 20100305123447/http://www.iub.edu/academic/index.shtml ... departments Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... siteindex Visit IU Bloomington Indiana University News RSS feed of 7 20100305123447/http://www.iub.edu/comments/index.shtml ... here ?Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... site indexVisit IU Bloomington Indiana University News RSS feed of 8 20100305123447/http://www.iub.edu/student/index.shtml ... consultants Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... siteindex Visit IU Bloomington Indiana University News RSS feed of 9 20100305123447/http://www.iub.edu/about/index.shtml ... Bloomington Campus Info 107 S. Indiana Ave. Bloomington, IN 47405 ... siteindex Visit IU Bloomington Indiana University News RSS feed of
Total hits is the number of records found!!
4. Use Nutch on Tomcat servers
Copy nutch-1.0.war (under root folder of Nutch) to webapps under Tomcat installation folder, and rename it to search.war. Start Tomcat to let it automatically extract contents from this archive. Modify nutch-site.xml in tomcat\webapps\search\WEB-INF\classes; add the following property:
This is to specify the targeted search directory, i.e. where you put the crawled contents.
Special note to Chinese users.
Then modify server.xml in tomcat\conf, identify the "Connector" part and add
URIEncoding="UTF-8" useBodyEncodingForURI="true"
We use URIEncoding="UTF-8" useBodyEncodingForURI="true" here to solve Chinese character encoding problem.
Then you can restart Tomcat, then type http://localhost:8080/search to the Nutch search page. Then you have set up a search engine now!!
Here is a screenshot. Have fun!!

{kind=link}
Thursday, March 4, 2010
一撮生命的清茶
在BYR上看到一首“打油诗”:
青瓷传清茶,接杯交盏。君莫怜,只有酒醉人。 娇花映鲛人,泪织绮罗。月无言,徒留魂梦欺。
看到“清茶”二字,想起来下边这个典故。
一个屡屡失意的年轻人千里迢迢来到普济寺,慕名寻到老僧释圆,沮丧地对他说:“人生总不如意,活着也是苟且,有什么意思呢?”
释圆静静听着年轻人的叹息和絮叨,末了才吩咐小和尚说:“施主远道而来,烧一壶温水送过来。”
稍顷,小和尚送来了一壶温水,释圆抓了茶叶放进杯子,然后用温水沏了,放在茶几上,微笑着请年轻人喝茶。杯子冒出微微的水汽,茶叶静静地浮着。年轻人不解地询问:“宝刹怎么用温茶?”
释圆笑而不语。年轻人喝一口细品,不由得摇摇头:“一点茶香都没有呢。”释圆说:“这可是闽地名茶铁观音啊。”年轻人又端起杯子品尝,然后肯定地说:“真的没有一丝茶香。”
释圆又吩咐小和尚:“再去烧一壶沸水送过来。”稍顷,小和尚便提着一壶冒着浓浓白汽的沸水进来。释圆起身,又取过一个杯子,放茶叶,倒沸水,再放在茶几上。年轻人俯首看去,茶叶在杯子里上下沉浮,丝丝清香不绝如缕,望而生津。
年轻人想要去端杯,释圆挡开,又提起水壶注入一线沸水。茶叶翻腾得更厉害了,一缕更醇厚更醉人的茶香袅袅升腾,在禅房里弥漫开来。释圆一共注了五次水,杯子终于满了,那绿绿的一杯茶水,端在手上清香扑鼻,入口沁人心脾。
释圆笑着问:“施主可知道,同是铁观音,为什么茶味相差这么大吗?”
年轻人思忖着说:“一杯用温水,一杯用沸水,冲沏的水不同。”释圆点头:“用水不同,茶叶的沉浮就不一样。温水沏茶,茶叶轻浮于水上,怎会散发清香?沸水沏茶,反复几次,茶叶沉沉浮浮,才能释放出茶的清香。世间芸芸众生,又何尝不是沉浮的茶叶呢?那些不经风雨的人,就像温水沏的茶叶,只在生活表面漂浮,根本浸泡不出生命的芳香;而那些栉风沐雨的人,如被沸水冲沏的酽茶,在沧桑岁月里几度沉浮,才有那沁人的清香啊。”
浮生若茶,我们何尝不是一撮生命的清茶?命运又何尝不是一壶温水或炽热的沸水呢?茶叶因为沉浮才释放了本身的清香,而生命,也只有遭遇一次次挫折和坎坷,才激发出人生那一脉脉幽香。
Wednesday, March 3, 2010
Statistical Learning Algorithm - Expectation Maximization
In machine learning, usually we are given a set of observed data, based on which we can do classification, clustering, etc. Classical techniques involved in these scenarios include Naive Bayes Classifier, Decision Tree Learning, K-means, KNN (K-nearest neighbors), etc. However, there may be situations when un-observed data or hidden variables are present. Expectation Maximization (EM) method is such a important statistical algorithm used to estimate the parameters in probabilistic models, where the models may depend on unobserved latent variables. In this sense, EM is similar with MLE (Maximum Likelihood Estimation) method. However, EM is basically a iterative method, which means that it needs to modify its estimates in each iteration, which makes it also similar with K-means. They both hold the "Gradient Descent" or "Hill Climbing" property; the drawback of these two approaches is then obvious: if the algorithm is not initialized well, it may encounter "local-maxima" problem!
 i <-
i <-  j Pij*(Xj - Ui)(Xj - Ui)'/Pi
j Pij*(Xj - Ui)(Xj - Ui)'/Pi
We will start with a description of general EM algorithm; after that we focus on its application in Gaussian Mixture Model (GMM), which is important and widely used.
The EM algorithm seeks to find the MLE by iteratively applying the following two major steps:
Expectation Step:
Calculate the expected value of the likelihood function as we discussed in MLE method. This expected value should be based on the conditional distribution of the hidden variables given the partially observed dataset under the current estimates of parameters. We call this expected value G(arg).
Maximization Step:
Update the paramters we are currently working on, choosing new parameters that will maximize G(arg) through some special schemes. Sometimes this scheme may be taking the weighted average of current parameters.
Of course, EM will need to initialize the parameters that would be estimated, just like what we did in a K-means algorithm: generally, any hill-climbing techniques will have similar problem. How to select the initial values? Randomly (The default method)? Or use some special techniques? The result of EM algorithm, as will be discussed later, is heavily dependent on "where we started".
Example: EM Algorithm in Gaussian Mixture Models
Clusters in data often comes from a mixture distribution, which may have k components. A datapoint is obtained by choosing a component and then apply that component to generate a sample. As for continuous data, a natural choice of probabilistic model is the multivariate Gaussian, which forms the mixture of Gaussian distributions. The parameters of a GMM are Wi = P(C = i), i.e. the weight of each component, Ui, i.e. the mean of each component, and  i, the covariance of each component.
i, the covariance of each component.
This basic idea of EM in this context is to pretend that we know the parameters of the model, and then to infer the probability that each datapoint belongs to each component. After that, we refit the components to the data, where each component is fitted to the entire data set with each point weighted by the probability that it belongs to that component. This process iterates until convergence. The hidden variables, in this case, would be which distribution component each datapoint belongs to. For the mixture of Gaussians, we randomly innitialize parameters for the mixture model, and then repeat following steps:
1. E - Step
Compute Pij = P(C = i Xj), which is the probability that datapoint Xj was generated by component Ci. By Bayes' rules, we have Pij = alpha*P(Xj C = i)*P(C = i), where alpha is a normalizer. P(Xj C = i) is just the probability density at Xj of the component Ci, and P(C = i) is the weight of Ci. Let Pi =  j Pij.
j Pij.
2. M - Step
Update the mean, covariance, and component weights as follows.
Ui <-  j Pij*Xj/Pi
j Pij*Xj/Pi
 i <-
i <-  j Pij*(Xj - Ui)(Xj - Ui)'/Pi
j Pij*(Xj - Ui)(Xj - Ui)'/Pi Wi <- Pi.
One thing to mention is, EM increases the log likelihood of the data at every iteration. In some situation, as discussed above, EM will reach a local maxima. A Matlab implementation of EM algorithm for Gaussian Mixture Models is attached here.
--------------------Matlab Codes for EM-GMM-------------------------
function [means, covs, weights, probDens, maxVals, maxIDs] = EMGaussianMixtureModel(dataset, k)% This is an EM algorithm for estimating parameters in Gaussian Mixture% Model% 'dataset' is the data ready for cluster% 'k' is the number of Gaussian components
% Get the dimension of each data pointdim = length(dataset(1, :));
% Get the number of data points in this datasetnum = length(dataset(:, 1));
% Initialize the weight uniformly for each Gaussian modelweights = zeros(k, 1);
for i = 1 : k weights(i) = 1/k;end
% Initialize means for each Gaussian modelmeans = zeros(k, dim);
% Initialize covariance matrix for each Gaussian modelcovs = zeros(dim, dim, k);
for i = 1 : k A = randn(dim, dim); covs(:, :, i) = A*A';end
% Initialize the probability table where probTable(X, i) stores the% probability that data point X was generated by component iprobTable = zeros(num, k);
% Begin EM AlgorithmnotConverge = 1;iterCount = 0;maxCount = 1000;
while(notConverge) % Expectation Step % Iterate the dataset to fill 'probTable' iterCount = iterCount + 1; for i = 1 : k for j = 1 : num p = mvnpdf(dataset(j, :), means(i, :), covs(:, :, i)); w = weights(i); % Save this the this probability to corresponding position in % the table % Note that the values computed here need to be normalized % later probTable(j, i) = p * w; end end % Normalize the probabilities we have just computed for i = 1 : length(probTable(:, 1)) total = sum(probTable(i, :)); for j = 1 : k probTable(i, j) = probTable(i, j)/total; end end % Maximization Step % Compute new mean, covariance matrix and weights for each Gaussian % model % We need to save current parameters for convergence checking tempWeights = weights; tempMeans = means; tempCovs = covs; for j = 1 : k pi = sum(probTable(:, j)); means(j, :) = zeros(1, dim); covs(:, :, j) = zeros(dim, dim); for i = 1 : num data = dataset(i, :); means(j, :) = means(j, :) + (probTable(i, j)/pi) * data; covs(:, :, j) = covs(:, :, j) + (probTable(i, j)/pi) * (data - means(j, :))' * (data - means(j, :)); end weights(j) = pi; end % Normalize the weights total = sum(weights); for i = 1 : k weights(i) = weights(i)/total; end % Check convergence threshold = 0.001; flag = 1; for j = 1 : k if (max(abs(tempWeights - weights)) > threshold) flag = 0; break; end if (max(abs(tempMeans - means)) > threshold) flag = 0; break; end if (max(abs(tempCovs - covs)) > threshold) flag = 0; break; end end if flag == 1 notConverge = 0; end % If iteration takes too long, we need to terminate it if iterCount > maxCount notConverge = 0; endend
% Now compute the probability density P(C = i Xj)probDens = zeros(num, k);
% This is P(C = i, Xj)for j = 1 : k for i = 1 : num probDens(i, j) = weights(j) * mvnpdf(dataset(i, :), means(j, :), covs(:, :, j)); endend
% This is P(C = i Xj)for i = 1 : num % This is P(Xj) total = sum(probDens(i, :)); for j = 1 : k probDens(i, j) = probDens(i, j)/total; endend
% Save the max value and their indices[maxVals, maxIDs] = max(probDens, [], 2);
% Begin plot the resultsfigure;
hold on;
for i = 1 : length(dataset) if maxIDs(i) == 1 plot(dataset(i, 1), dataset(i, 2), 'o', 'MarkerEdgeColor', 'r', 'MarkerFaceColor', 'r'); elseif maxIDs(i) == 2 plot(dataset(i, 1), dataset(i, 2), 'o', 'MarkerEdgeColor', 'g', 'MarkerFaceColor', 'g'); elseif maxIDs(i) == 3 plot(dataset(i, 1), dataset(i, 2), 'o', 'MarkerEdgeColor', 'b', 'MarkerFaceColor', 'b'); endend
hold off;
end
Monday, March 1, 2010
Statistical Learning Algorithm - Maximum Likelihood Estimation
Maximum Likelihood Estimation (MLE) is a statistical method used for estimating parameters of some statistical model that may be fitted for existing data. The idea behind MLE is simple: Given a set of observations, we need to choose the parameters that maximizes the likelihood that this statistical model produces these data.
2. How to Compute MLE
1. General Ideas
Two cases, discrete and continuous populations, are involved in discussion. We only discuss the situation where X is a continuous variable; cases for discrete variables are basically very similar.
Assume X is a continuous variable, and it probability density function (PDF) is  and X1, X2, ..., Xn are samples from the population. X1, X2, ..., Xn are independent and identically distributed (i.i.d.). Thus the cumulative probability density should be
and X1, X2, ..., Xn are samples from the population. X1, X2, ..., Xn are independent and identically distributed (i.i.d.). Thus the cumulative probability density should be  . When
. When  are fixed values, this is exactly the probability density at X1 = x1, X2 = x2, ..., Xn = xn; but when x1, x2, ..., xn are given, it becomes a function of
are fixed values, this is exactly the probability density at X1 = x1, X2 = x2, ..., Xn = xn; but when x1, x2, ..., xn are given, it becomes a function of  . We call this new function
. We call this new function  likelihood function. The significance of
likelihood function. The significance of  is that it represents the likelihood of the given observations; as we have "observed" those data, then we need to maximize their probability through this function, i.e. we need to choose the parameters that maximize
is that it represents the likelihood of the given observations; as we have "observed" those data, then we need to maximize their probability through this function, i.e. we need to choose the parameters that maximize  .
.
 and X1, X2, ..., Xn are samples from the population. X1, X2, ..., Xn are independent and identically distributed (i.i.d.). Thus the cumulative probability density should be
and X1, X2, ..., Xn are samples from the population. X1, X2, ..., Xn are independent and identically distributed (i.i.d.). Thus the cumulative probability density should be  . When
. When  are fixed values, this is exactly the probability density at X1 = x1, X2 = x2, ..., Xn = xn; but when x1, x2, ..., xn are given, it becomes a function of
are fixed values, this is exactly the probability density at X1 = x1, X2 = x2, ..., Xn = xn; but when x1, x2, ..., xn are given, it becomes a function of  . We call this new function
. We call this new function  likelihood function. The significance of
likelihood function. The significance of  is that it represents the likelihood of the given observations; as we have "observed" those data, then we need to maximize their probability through this function, i.e. we need to choose the parameters that maximize
is that it represents the likelihood of the given observations; as we have "observed" those data, then we need to maximize their probability through this function, i.e. we need to choose the parameters that maximize  .
. 2. How to Compute MLE
Suppose we now have a group of observations X1, X2, ..., Xn, and we need to estimate those parameters that would maximize that likelihood function mentioned above. This is where the name "Maximum Likelihood Estimation" comes from. The log() is a monotonically increasing function, so we have:

To get parameters that maximize L is the same to maximize log(L). In most cases, it is much easier to do so. We compute derivatives of log(L) with respect to  , and let them to be zero. Then we get the following:
, and let them to be zero. Then we get the following:

This is called the system of likelihood equations. The solutions of the above equation system, if can be verified to maximize L, are exactly the parameters we need to get. Sometimes, the solutions may be multiple, so further steps is required to distinguish which solution gives the parameters we want.
Data Clustering Algorithm - K-means
K-means is a very basic but still very powerfull clustering algorithm. It aims to partition observations into k clusters in which each observation belongs to the cluster with the nearest distance. This is probably most widely used algorithm, compared to other machine learning techniques.
Intuitively, we now introduce major steps and some of their details in a simple K-means implementation.
Step 1: Initialization of K centroids
Centroid is a important concept here. The centroid is the center of one cluster. K-means is actually a iterative method. Centroids are updated through iterations, by computing the means of all current datapoints in one cluster. However, the initialization of centroids is very tricky, and will have a great impact on the clustering result. By default, the centroids are selected randomly from the datapoints in the given dataset. But various improvements are now available. Random, Forgy, MacQueen and Kaufman are four good examples. Discussions about them are available here.
Step 2: Assignment of datapoints to nearest centroids
In this step, we need to compute the distances from each datapoint to these K centroids. Based on these distance information, we assign a "nearest" centroid to each datapoint. The word "nearest" is quoted because another tricky thing will happen: what distance measure are we going to use? Again, the default measure is the euclidean distance. But this choice should depend on different situations. Some new distance measures like walk-based or ontology-based, etc are emerging for different needs.
Step 3: Update the centroids
After we have obtained these distance information (we can actually save them in a hash table or similar structure), we need to update the centroids. The new centroids are computed by taking the means of all datapoints in one "current" cluster. I put the word "current" because the clusters are changing all the time.
All we need to do now is to iterate these steps until the algorithm converges. Yes, it will, usually. The convergence properties are discussed here.
I have attached a matlab version of K-means algorithm here. It is a very simple implementation: random initialization and plain Euclidean distance are adopted. This is only for you to have a general concept of what this algorithm do.
-----------------K-means Algorithm - Matlab Implementation------------------
function [labels] = KMeansCluster(dataset, k)% This is a matlab version of a simple K-Means algorithm% 'dataset' is the data ready for cluster% 'k' is the number of clusters
% Dimension of each datapointdim = length(dataset(1, :));
% Number of datapoints in the given datasetnum = length(dataset);
% Initialize labels for datapointslabels = zeros(num, 1);
% Initialize centroids for this datasetcentroids = zeros(k, dim);
% Initialize k centroids% Default method - randomly choose k datapointscentIDs = randint(k, 1, num);for i = 1 : k centroids(k, :) = dataset(centIDs(i), :);end
% K-Means BeginnotConverge = 1;threshold = 0.001;maxIter = 1000;iterCount = 0;
while notConverge % Compute distances from each datapoint to these k centroids, and % assign each datapoint a cluster label % Create a table to save all intermediate distance information distTable = zeros(num, k); for i = 1 : num data = dataset(i, :); for j = 1 : k % Use simple Euclidean distance distTable(i, j) = pdist([data; centroids(j, :)], 'euclidean'); end end % Assignment Step [Y, labels] = min(disTable, [], 2); % Update Step % Compute new centroids % Save previous centroids for convergence checking tempCentroids = centroids; for i = 1 : k total = zeoros(1, dim); count = 0; for j = 1 : num if labels(j) == i total = total + dataset(j, :); count = count + 1; end end centroids(i, :) = total/count; end % Check convergence if max(abs(centroids - tempCentroids) < notconverge =" 0;" itercount =" iterCount"> maxIter break; endendend
Intuitively, we now introduce major steps and some of their details in a simple K-means implementation.
Step 1: Initialization of K centroids
Centroid is a important concept here. The centroid is the center of one cluster. K-means is actually a iterative method. Centroids are updated through iterations, by computing the means of all current datapoints in one cluster. However, the initialization of centroids is very tricky, and will have a great impact on the clustering result. By default, the centroids are selected randomly from the datapoints in the given dataset. But various improvements are now available. Random, Forgy, MacQueen and Kaufman are four good examples. Discussions about them are available here.
Step 2: Assignment of datapoints to nearest centroids
In this step, we need to compute the distances from each datapoint to these K centroids. Based on these distance information, we assign a "nearest" centroid to each datapoint. The word "nearest" is quoted because another tricky thing will happen: what distance measure are we going to use? Again, the default measure is the euclidean distance. But this choice should depend on different situations. Some new distance measures like walk-based or ontology-based, etc are emerging for different needs.
Step 3: Update the centroids
After we have obtained these distance information (we can actually save them in a hash table or similar structure), we need to update the centroids. The new centroids are computed by taking the means of all datapoints in one "current" cluster. I put the word "current" because the clusters are changing all the time.
All we need to do now is to iterate these steps until the algorithm converges. Yes, it will, usually. The convergence properties are discussed here.
I have attached a matlab version of K-means algorithm here. It is a very simple implementation: random initialization and plain Euclidean distance are adopted. This is only for you to have a general concept of what this algorithm do.
-----------------K-means Algorithm - Matlab Implementation------------------
function [labels] = KMeansCluster(dataset, k)% This is a matlab version of a simple K-Means algorithm% 'dataset' is the data ready for cluster% 'k' is the number of clusters
% Dimension of each datapointdim = length(dataset(1, :));
% Number of datapoints in the given datasetnum = length(dataset);
% Initialize labels for datapointslabels = zeros(num, 1);
% Initialize centroids for this datasetcentroids = zeros(k, dim);
% Initialize k centroids% Default method - randomly choose k datapointscentIDs = randint(k, 1, num);for i = 1 : k centroids(k, :) = dataset(centIDs(i), :);end
% K-Means BeginnotConverge = 1;threshold = 0.001;maxIter = 1000;iterCount = 0;
while notConverge % Compute distances from each datapoint to these k centroids, and % assign each datapoint a cluster label % Create a table to save all intermediate distance information distTable = zeros(num, k); for i = 1 : num data = dataset(i, :); for j = 1 : k % Use simple Euclidean distance distTable(i, j) = pdist([data; centroids(j, :)], 'euclidean'); end end % Assignment Step [Y, labels] = min(disTable, [], 2); % Update Step % Compute new centroids % Save previous centroids for convergence checking tempCentroids = centroids; for i = 1 : k total = zeoros(1, dim); count = 0; for j = 1 : num if labels(j) == i total = total + dataset(j, :); count = count + 1; end end centroids(i, :) = total/count; end % Check convergence if max(abs(centroids - tempCentroids) < notconverge =" 0;" itercount =" iterCount"> maxIter break; endendend
龙应台:美国不是我们的家
按:我不知道为何那些讨论是否回国的帖子为何会思考的如此犬儒主义,作为要出国或已 出国的同学我们是不是把曾经重视的那些价值与责任给忘了。所以转载龙应台女士25年前 野火集里的一篇文章。愿意思考这类问题的就看一看吧!
----------------------------------------------------------------- 美国不是我们的家
我收到好几十封读者的来信。年长一点的说:"每看你的文章,心情激动难平,一再泪下 。"年轻一点的大学生写着:"在成为冷漠的社会人之前,请告诉我们:我们能为台湾这个 母亲做些什么?"更年轻的,高中生,说:"反正做什么都没有用:我大学毕业就要远走高 飞,到美国去!" ※ ※ ※
少年人激动愤慨,老人家伤心落泪,绝对不是因为我的文章写得好。这一大叠情绪汹涌的 信件对有心人应该透露出两个问题:第一是事态本身的严重性;台湾生活环境的恶劣已经 不是知识分子庸人自扰的嚷嚷,而是市井小民身受的痛苦。第二是个人的无力感;如果这 个社会制度中有畅通的管道让小市民去表达他的意愿、去实现他的要求,他就不会郁积到 近乎爆炸的程度,就不需要凭靠区区几篇不起眼的文章来发泄他的痛苦。 第二个问题要比第一个还严重得多。因为环境再恶劣,难题再复杂,个人如果有适当的途 径去解决问题,觉得享有可为,他总是肯定的、理性的、乐观进取的。反过来说,即使问 题本身并不那么恶劣,但是个人觉得他的一切努力都是一条死巷,他的愤懑锁在堵塞的管 道中时,人,是会爆炸的。 半年前,有个爱看书的青年因为受不了隔邻女人早晚不断地诵经,冲进了她的屋子拿刀杀 她。暴力当然没有任何藉口,但是我们要追究原因:如果这个青年只要打一通电话,警察 就会来取缔噪音的话,这件凶杀案是不是可以避免?换句话说,假使这个青年一通一通电 话的哀求警察而警察不管,一次一次地劝告诵经的妇人而妇人不睬;那么,你说;他可以 搬家——别开玩笑了,台北什么地方可以让人安静度日?于是,日日夜夜受噪音的煎熬, 又丝毫没有改善的可能,他到底该怎么办? ※ ※ ※
苏格拉底那个老头子被判了死刑之后,不愿逃狱,他说:"当我对一个制度不满时,我有 两条路:或者离开这个国家,或者循合法的途径去改变这个制度。但是我没有权利以反抗 的方式去破坏它。"(见《难局》,二月五日"人间") 不错,苏老头是个循规蹈矩的模范公民,但你是否注意到,做个好公民有两个先决条件: 首先,不肯妥协时,他有离开这个国家的自由;其次,这个国家必须供给他适当的管道去 改变他不喜欢的制度。也就是说,如果雅典政府既不许他离境,又不给予他改革的管道, 他就没有义务片面地做个循规蹈矩的公民。 那么我们的情况呢?台湾的生活环境恶劣,升斗小民所面临的选择与苏格拉底没有两样: 他可以离开台湾,但这有大多实际上的困难。他可以"循合法途径"去改变现状—— 我们有没有这个合法的途径、畅通的管道? ※ ※ ※
一位医生来信叙说他痛苦的经历。住宅区中突然出现一个地下铁工厂,噪音与废气使整个 社区变色。他从私下的恳求到公开的陈情控告,无所不试,结果,等于零。这个机构说法 令不全,那个部门说不是他家的事,警察更说开工厂的人可怜!这位医生伤心绝望地问: "政府到底在做什么?法律究竟在保护谁?" 连十七岁的高中生都理直气壮地说:"反正没有用!我要到美国去!" 你不为我们的前途担忧吗? 这份绝望的无力感是谁造成的? ※ ※ ※
许多人或许会把箭头指向政府——营建处、环保局、卫生署、警察局等等等,可是我不能 ,因为我的知识领域狭窄极了;我根本不知道垃圾有几种处理方式、食品进口要如何管制 、努力调动要如何分配。我不是专家,没有资格告诉这些在位做事的人怎么去做。 但是和你一样,我是个有充分资格的公民。无力感的根源或许是个鸡生蛋、蛋生鸡的问题 ;你或许觉得缺乏畅通的管道咎在政府,我却认为,你和我之所以有无力感,实在是因为 我们这些市并小民不懂得争取自己的权利,纵容了那些为我们做事的人。咎在我们自己。 大多数的中国人习惯性地服从权威——任何一个人坐在柜台或办公桌后面,就是一个权威 。我看见学生到邮局取款,填错了单子,被玻璃后的小姐骂得狗血喷头。这位学生唯唯诺 诺,惊恐万分。我也看见西装笔挺的大男人到区公所办事,戴眼镜的办事员冷眼一翻,挥 挥手:"去去去!都快十二点了,还来干什么?"大男人哈腰赔笑,求他高抬贵手。我更知 道一般的大学生,在面对一个拆"烂污"的老师时,不是翘课以逃避,就是附和以顺从。 到邮局取款,拿的是自己的钱,填错单子可以再填,学生为什么却觉得办事小姐有颐指气 使的权利?区公所的职员,不到钟点就理应办公,大男人为什么要哀求他?学生缴了学费 来求知识,就有权利要求老师认真尽职,为什么老师不做好,学生也无所谓? 所谓政府——警察局、卫生署、环保局——都是你和我这些人辛辛苦苦工作,用纳了税的 钱把一些人聘雇来为我们做事的。照道理说,这些人做不好的时候,你和我应该手里拿着 鞭子,睁着雪亮的眼睛,严厉地要求他们改进;现在的情况却主仆颠倒,这些受雇的人做 不好,我们还让他声色俱厉地摆出"父母官"的样子来把我们吓得半死,脑袋一缩,然后大 叹"无力"! 连自己是什么人都不知道,连这个主雇关系都没弄清楚,我们还高喊什么"民主、伦理、 科学"? ※ ※ ※
每天清早,几万个衣履光洁的人涌进开往纽约市区的火车到城中上班。车厢内冬天没有暖 气,夏天冷气故障,走三步要抛锚两步,票价还贵得出奇。可是因为是垄断事业,所以日 复一日,年复一年,人人抱怨,人人还是每天乖乖地上车。一直到史提夫受不了了,他每 天奔走,把乘客组织起来,拒乘火车,改搭汽车。同时,火车一误点,就告到法庭去要求 赔偿。他跟铁路公司"吃不完,兜着走"。 史提夫没有无力感。 ※ ※ ※
安东妮十三岁的女儿被酒后驾车的人撞死了。因为是过失杀人,所以肇事者判的刑很轻, 但是安东妮只有一个不能复生的女儿,这个平凡的家庭主妇开始把关心的母亲聚集起来, 去见州长,州长不见,她就在会客室里从早上八点枯坐到下午五点,不吃午餐。两年的努 力下来,醉酒驾车的法令修正了,警察路检的制度加严了。别的母亲,或许保住了她们十 三岁的女儿。 安东妮也没有无力感。 ※ ※ ※
我并没有史提夫和安东妮的毅力。人生匆促得可怕,忙着去改革社会,我就失去了享受生 活的时间。大部分的时候,我宁可和孤独的梭罗一样,去看云、看山、看田里的水牛与鹭 鸶。不过,我们不做大人物,总可以做个有一点用的小人物吧?一个渺小的个人,如你, 如我,还是可以发光发热。过程会很困难,没错;有些人会被牺牲,没错。可是,在你没 有亲身试过以前,你不能说"不可能"!在你没有努力奋斗过以前,你也不能谈"无力感"。 问问史提夫,问问安东妮。 讲"道德勇气",不是可耻的事,说"社会良知",也并不肤浅。受存在主义与战乱洗礼的现 代人以复杂悲观自许,以深沉冷漠为傲;你就做个简单却热诚的人吧!所需要的,只是那 么一丁点勇气与天真。你今天多做一点,我们就少一个十七岁的说:"反正没有用,我到 美国去!" 美国,毕竟不是我们的家。 -- 最想要去的地方,怎能在半路就返航?
----------------------------------------------------------------- 美国不是我们的家
我收到好几十封读者的来信。年长一点的说:"每看你的文章,心情激动难平,一再泪下 。"年轻一点的大学生写着:"在成为冷漠的社会人之前,请告诉我们:我们能为台湾这个 母亲做些什么?"更年轻的,高中生,说:"反正做什么都没有用:我大学毕业就要远走高 飞,到美国去!" ※ ※ ※
少年人激动愤慨,老人家伤心落泪,绝对不是因为我的文章写得好。这一大叠情绪汹涌的 信件对有心人应该透露出两个问题:第一是事态本身的严重性;台湾生活环境的恶劣已经 不是知识分子庸人自扰的嚷嚷,而是市井小民身受的痛苦。第二是个人的无力感;如果这 个社会制度中有畅通的管道让小市民去表达他的意愿、去实现他的要求,他就不会郁积到 近乎爆炸的程度,就不需要凭靠区区几篇不起眼的文章来发泄他的痛苦。 第二个问题要比第一个还严重得多。因为环境再恶劣,难题再复杂,个人如果有适当的途 径去解决问题,觉得享有可为,他总是肯定的、理性的、乐观进取的。反过来说,即使问 题本身并不那么恶劣,但是个人觉得他的一切努力都是一条死巷,他的愤懑锁在堵塞的管 道中时,人,是会爆炸的。 半年前,有个爱看书的青年因为受不了隔邻女人早晚不断地诵经,冲进了她的屋子拿刀杀 她。暴力当然没有任何藉口,但是我们要追究原因:如果这个青年只要打一通电话,警察 就会来取缔噪音的话,这件凶杀案是不是可以避免?换句话说,假使这个青年一通一通电 话的哀求警察而警察不管,一次一次地劝告诵经的妇人而妇人不睬;那么,你说;他可以 搬家——别开玩笑了,台北什么地方可以让人安静度日?于是,日日夜夜受噪音的煎熬, 又丝毫没有改善的可能,他到底该怎么办? ※ ※ ※
苏格拉底那个老头子被判了死刑之后,不愿逃狱,他说:"当我对一个制度不满时,我有 两条路:或者离开这个国家,或者循合法的途径去改变这个制度。但是我没有权利以反抗 的方式去破坏它。"(见《难局》,二月五日"人间") 不错,苏老头是个循规蹈矩的模范公民,但你是否注意到,做个好公民有两个先决条件: 首先,不肯妥协时,他有离开这个国家的自由;其次,这个国家必须供给他适当的管道去 改变他不喜欢的制度。也就是说,如果雅典政府既不许他离境,又不给予他改革的管道, 他就没有义务片面地做个循规蹈矩的公民。 那么我们的情况呢?台湾的生活环境恶劣,升斗小民所面临的选择与苏格拉底没有两样: 他可以离开台湾,但这有大多实际上的困难。他可以"循合法途径"去改变现状—— 我们有没有这个合法的途径、畅通的管道? ※ ※ ※
一位医生来信叙说他痛苦的经历。住宅区中突然出现一个地下铁工厂,噪音与废气使整个 社区变色。他从私下的恳求到公开的陈情控告,无所不试,结果,等于零。这个机构说法 令不全,那个部门说不是他家的事,警察更说开工厂的人可怜!这位医生伤心绝望地问: "政府到底在做什么?法律究竟在保护谁?" 连十七岁的高中生都理直气壮地说:"反正没有用!我要到美国去!" 你不为我们的前途担忧吗? 这份绝望的无力感是谁造成的? ※ ※ ※
许多人或许会把箭头指向政府——营建处、环保局、卫生署、警察局等等等,可是我不能 ,因为我的知识领域狭窄极了;我根本不知道垃圾有几种处理方式、食品进口要如何管制 、努力调动要如何分配。我不是专家,没有资格告诉这些在位做事的人怎么去做。 但是和你一样,我是个有充分资格的公民。无力感的根源或许是个鸡生蛋、蛋生鸡的问题 ;你或许觉得缺乏畅通的管道咎在政府,我却认为,你和我之所以有无力感,实在是因为 我们这些市并小民不懂得争取自己的权利,纵容了那些为我们做事的人。咎在我们自己。 大多数的中国人习惯性地服从权威——任何一个人坐在柜台或办公桌后面,就是一个权威 。我看见学生到邮局取款,填错了单子,被玻璃后的小姐骂得狗血喷头。这位学生唯唯诺 诺,惊恐万分。我也看见西装笔挺的大男人到区公所办事,戴眼镜的办事员冷眼一翻,挥 挥手:"去去去!都快十二点了,还来干什么?"大男人哈腰赔笑,求他高抬贵手。我更知 道一般的大学生,在面对一个拆"烂污"的老师时,不是翘课以逃避,就是附和以顺从。 到邮局取款,拿的是自己的钱,填错单子可以再填,学生为什么却觉得办事小姐有颐指气 使的权利?区公所的职员,不到钟点就理应办公,大男人为什么要哀求他?学生缴了学费 来求知识,就有权利要求老师认真尽职,为什么老师不做好,学生也无所谓? 所谓政府——警察局、卫生署、环保局——都是你和我这些人辛辛苦苦工作,用纳了税的 钱把一些人聘雇来为我们做事的。照道理说,这些人做不好的时候,你和我应该手里拿着 鞭子,睁着雪亮的眼睛,严厉地要求他们改进;现在的情况却主仆颠倒,这些受雇的人做 不好,我们还让他声色俱厉地摆出"父母官"的样子来把我们吓得半死,脑袋一缩,然后大 叹"无力"! 连自己是什么人都不知道,连这个主雇关系都没弄清楚,我们还高喊什么"民主、伦理、 科学"? ※ ※ ※
每天清早,几万个衣履光洁的人涌进开往纽约市区的火车到城中上班。车厢内冬天没有暖 气,夏天冷气故障,走三步要抛锚两步,票价还贵得出奇。可是因为是垄断事业,所以日 复一日,年复一年,人人抱怨,人人还是每天乖乖地上车。一直到史提夫受不了了,他每 天奔走,把乘客组织起来,拒乘火车,改搭汽车。同时,火车一误点,就告到法庭去要求 赔偿。他跟铁路公司"吃不完,兜着走"。 史提夫没有无力感。 ※ ※ ※
安东妮十三岁的女儿被酒后驾车的人撞死了。因为是过失杀人,所以肇事者判的刑很轻, 但是安东妮只有一个不能复生的女儿,这个平凡的家庭主妇开始把关心的母亲聚集起来, 去见州长,州长不见,她就在会客室里从早上八点枯坐到下午五点,不吃午餐。两年的努 力下来,醉酒驾车的法令修正了,警察路检的制度加严了。别的母亲,或许保住了她们十 三岁的女儿。 安东妮也没有无力感。 ※ ※ ※
我并没有史提夫和安东妮的毅力。人生匆促得可怕,忙着去改革社会,我就失去了享受生 活的时间。大部分的时候,我宁可和孤独的梭罗一样,去看云、看山、看田里的水牛与鹭 鸶。不过,我们不做大人物,总可以做个有一点用的小人物吧?一个渺小的个人,如你, 如我,还是可以发光发热。过程会很困难,没错;有些人会被牺牲,没错。可是,在你没 有亲身试过以前,你不能说"不可能"!在你没有努力奋斗过以前,你也不能谈"无力感"。 问问史提夫,问问安东妮。 讲"道德勇气",不是可耻的事,说"社会良知",也并不肤浅。受存在主义与战乱洗礼的现 代人以复杂悲观自许,以深沉冷漠为傲;你就做个简单却热诚的人吧!所需要的,只是那 么一丁点勇气与天真。你今天多做一点,我们就少一个十七岁的说:"反正没有用,我到 美国去!" 美国,毕竟不是我们的家。 -- 最想要去的地方,怎能在半路就返航?
名妓、名媛和婊子
发信人: GGMM1977 (GGMM1977), 信区: WaterWorld标 题: 名妓、名媛、和婊子 (原创首发)发信站: BBS 未名空间站 (Thu Feb 11 13:40:23 2010, 美东)
谁也没想到,中国2010年最火爆的消息不是什么中美两国经贸纠纷,不是谷歌PK中国新闻检查,也不是海地大地震,甚至也不是丰田车出事,而是京城里最近闹出的那场名人之间的风波。 本人从来不看花边新闻,这一次眼球也给抓住了,可见这场风波之精彩出众,激烈非凡。
这场风波到底是婊子PK戏子,还是名旦PK名媛,现在公众还没有定论。 但从目前的爆料来看, 双方都不是什么清纯玉女,更不是妇道人家。 虽然谁胜谁负已经基本上见分晓了,但不能保证今后没有更精彩的爆料。 所以好戏还有得看。
要看戏至少要明白一场戏中的主要角色。 这场戏中的角色有些特殊。 为了搞清楚这些角色,本文介绍三个重要的概念:名妓、婊子、和名媛。
什么是名妓呢? 名妓本质上也是靠出卖肉体为生的妓女,只不过妓艺高超,达到了炉火纯青的地步,所以就被人们称为名妓。名妓首先必须是天生丽质,袅娜娉婷、楚楚依人,沉鱼落雁,闭月羞花,一笑倾城,二笑倾国,三笑城国颓倾。 有的时候,名妓还要精通房中之术,床第功夫一流,既可以把男人伺候得欲仙欲死,又不至于淫乱宫闱。 最后,名妓还要身手不凡,既会琴棋诗画, 又长袖善舞,知书达理。 总而言之,名妓是上得了龙床,下得了茅房的高级妓女。 中国历史上出了无数名妓,如苏小小、谢阿蛮、霍小玉、杜秋娘、柳如是、章台柳、刘婆惜、杜十娘、卞玉京、董小婉、陈圆圆、赛金花、小凤仙等等。 这其中不乏善良正直、忧国忧民的名妓。 旧时代妇女的命运不由自己掌握,坠入青楼多为生活、命运所逼。 但她们之中也有人良心未泯,利用自己的特殊身份干出惊天动地的大事的。 当然,这不过是名妓中的另类。 大多数名妓是永远不会有良心发现的,能不纵容她们的男人祸国殃民就很不错了。
什么是婊子呢? 咋一看婊子很像妓女,多半也是以卖X为生,但档次要低得多了。 婊子又名二奶、小三等。 其实,人们对于婊子有许多误解。 并不是所有和别人老公发生关系的女人都是婊子。 女人和别人的老公睡觉不外乎两个原因:(1)性爱的原始冲动 (2)为利益所驱动。 出于原始性爱的婚外情最多不过是太傻、太痴情或太骚,大不了是个骚女人而已,算不上婊子,况且多数情况下还是臭男人的错。 纯粹出于利益驱使和任何男人发生关系的女人,就是婊子了。 那么,婊子与妓女最大的区别是什么呢? 妓女出卖自己的肉体多半出于无奈,实在是走投无路了,只好坠入青楼。 这是被动的。 而婊子却常常是主动的。 婊子往往并不愁衣食,甚至有不错的收入。 但她们却可以随时随地把裤子一脱和任何可以给她们带来更大利益的男人上床,拿自己的肉体换取更多的利益, 她们是一群无耻的女人。 婊子和妓女的根本区别在于,妓女只卖肉而不卖心,婊子既卖肉也卖心。 一个女人被迫当上了妓女还有从良的可能性,但一个女人一旦当上了婊子,就彻底没救了。 所以,历史上有的名妓身在青楼心系江山社稷,有的名妓为爱殉情,但你有听说过任何一个婊子有过任何轰轰烈烈的壮举吗? 照我说,婊子不过是一群上得了官场,搅得乱情场的贱货。
但婊子再贱也是人。 虽然她们以卖X为荣,但她们心底里也知道自己有多贱。 被人们在背后指指戳戳的味道也不好受。 夜深人静之时她们也有烦恼。 几千年来,“既要当婊子,又要立牌坊”一直是婊子们的梦。 无奈中国社会越发展,婊子们的地位越低下。 1955年中国开天辟地实行了一夫一妻婚姻制,婊子们更步履维艰。
但是,到了公元21世纪,风水轮回转,婊子们解放了! 她们的梦想终于实现了! 突然间,婊子们成了被社会尊敬、羡慕又惧怕的一群高尚的女人。 谈论自己和人家的男人上床的经历已经成了中国社会婊子族的时髦。 今天的婊子可以堂堂正正地宣称“我爱我的先生,虽然我们没有结婚,但这并不妨碍我为他生一个孩子,孩子是我们爱情的结晶!”(尽管她那位先生法定是别人的) 。 “我爱他,我愿意为他生孩子,这碍着谁了?”成了中国公元2010年的最强音。 什么婚姻法,什么一夫一妻制,什么家庭观念,什么礼仪廉耻,统统成了不入时的垃圾。
京城的婊子一夜之间成了京城名媛。
什么是名媛? 名媛是出身而不是职业。 名媛一词出自于清代李渔的《风筝误•艰配》:“婵娟争觑我,我也觑婵娟,把帝里名媛赶一日批评徧。” 名媛就是上得了厅堂,出得了闺房的名门闺秀。大观园中的黛玉小姐是名媛,闺中的宋庆龄、宋美龄是名媛,袁淑祯、袁静雪是名媛,赵四小姐是名媛,蒋碧薇是名媛,吴健雄是名媛。 红色贵族中,洪晃她妈是名媛,林立果他姐是名媛,毛新宇他姑姑是名媛,李小琳马马虎虎也算半个名媛吧。
那京城的赵小三凭哪一条算是名媛?
名媛会做泼墨那种下三烂的事情的吗?
古时候,一个默默无闻的宫女被皇上临幸了,皇恩便开始浩荡到她的身上。 要是怀上了龙种,从此妾便以子贵,苦尽甜来。 那虽说不尽风流,但也还算是名正言顺,毕竟人家进宫是办了正式手续的。 如今一个三流戏子被一个过气老帅府里的什么人(反正是别人的丈夫)搞了几次,包了几年,弄出个私生子,居然摇身一变,成了京城富甲天下、呼风唤雨、兴风作浪的贵妇了。 今天就连京城的皇家御林军都要甘拜下风,为这贵妇冲锋陷阵,保驾护航。 而一向对花边新闻大开绿灯的中宣部这一次也破例管起了这件事,开始清理网上的传言了。 半个国家都在为这位小三效劳。 这什么狗屁世道! 啥玩意嘛。
以前皇帝的女儿敢这么凶吗? 不敢。 这位小三不就是一个睡人家男人, 拿人家点施舍,靠着人家的权势狐假虎威的高级婊子吗? 幸亏临幸她的不过是过气老帅府上的某人而已。 她要是早生几年,被先帝给看中,又被先帝临幸了,那她还不成了当今国母,三军女帅,我们都要高喊女皇万岁万万岁? 遗憾啊,差来差去就差了个名分,导致她名不正言不顺,以至于她再说她跟她“先生”都“结晶”了,却还是不敢公布她“先生”的尊姓大名。 尽管她身着DIOR的网眼连衣裙,用PIAGET的珠宝腕表衬出自己的风采,还是不能掩饰她的职业:小三,或者说婊子。 不过婊子能做到这个规模,这步田地,也算是出类拔萃了。 所以说她是个“国婊”应该比较贴切。
至于那个国际章,我提都不想提。 如今,在中国连做婊子都不是什么见不得人的事情了,她的那些事情还有什么好谈的。 即使没有这场风波,她也谈不上清纯二字。 她又不是不知道她“姐姐”的底细,可还是自己找上门去,白沾了一身骚。 就算人家是诬陷她,可诈捐那件事是铁板钉钉的吧。 更何况,假如她跟她“姐姐”合伙的生意要是做成了呢? 要是那些传闻千真万确呢? 那我们就对她刮目相看了。 那些事情如果是真,那她就不是国际章,而是国妓章了。 但尽管那样她还算不上是个名妓。 杜十娘、陈圆圆、赛金花、小凤仙会做出诈捐那种丧尽天良的事情吗? 不会的。 所以说,她充其量最多是个国妓。 反正这个国家逼良为娼又不是一天两天的事情了。
但是比起国婊赵,国妓章还是嫩了点。 这场风波后还是跟着姐姐学着点为好。
一个国婊要PK一个国妓,这样的新闻不火爆也难。
谁也没想到,中国2010年最火爆的消息不是什么中美两国经贸纠纷,不是谷歌PK中国新闻检查,也不是海地大地震,甚至也不是丰田车出事,而是京城里最近闹出的那场名人之间的风波。 本人从来不看花边新闻,这一次眼球也给抓住了,可见这场风波之精彩出众,激烈非凡。
这场风波到底是婊子PK戏子,还是名旦PK名媛,现在公众还没有定论。 但从目前的爆料来看, 双方都不是什么清纯玉女,更不是妇道人家。 虽然谁胜谁负已经基本上见分晓了,但不能保证今后没有更精彩的爆料。 所以好戏还有得看。
要看戏至少要明白一场戏中的主要角色。 这场戏中的角色有些特殊。 为了搞清楚这些角色,本文介绍三个重要的概念:名妓、婊子、和名媛。
什么是名妓呢? 名妓本质上也是靠出卖肉体为生的妓女,只不过妓艺高超,达到了炉火纯青的地步,所以就被人们称为名妓。名妓首先必须是天生丽质,袅娜娉婷、楚楚依人,沉鱼落雁,闭月羞花,一笑倾城,二笑倾国,三笑城国颓倾。 有的时候,名妓还要精通房中之术,床第功夫一流,既可以把男人伺候得欲仙欲死,又不至于淫乱宫闱。 最后,名妓还要身手不凡,既会琴棋诗画, 又长袖善舞,知书达理。 总而言之,名妓是上得了龙床,下得了茅房的高级妓女。 中国历史上出了无数名妓,如苏小小、谢阿蛮、霍小玉、杜秋娘、柳如是、章台柳、刘婆惜、杜十娘、卞玉京、董小婉、陈圆圆、赛金花、小凤仙等等。 这其中不乏善良正直、忧国忧民的名妓。 旧时代妇女的命运不由自己掌握,坠入青楼多为生活、命运所逼。 但她们之中也有人良心未泯,利用自己的特殊身份干出惊天动地的大事的。 当然,这不过是名妓中的另类。 大多数名妓是永远不会有良心发现的,能不纵容她们的男人祸国殃民就很不错了。
什么是婊子呢? 咋一看婊子很像妓女,多半也是以卖X为生,但档次要低得多了。 婊子又名二奶、小三等。 其实,人们对于婊子有许多误解。 并不是所有和别人老公发生关系的女人都是婊子。 女人和别人的老公睡觉不外乎两个原因:(1)性爱的原始冲动 (2)为利益所驱动。 出于原始性爱的婚外情最多不过是太傻、太痴情或太骚,大不了是个骚女人而已,算不上婊子,况且多数情况下还是臭男人的错。 纯粹出于利益驱使和任何男人发生关系的女人,就是婊子了。 那么,婊子与妓女最大的区别是什么呢? 妓女出卖自己的肉体多半出于无奈,实在是走投无路了,只好坠入青楼。 这是被动的。 而婊子却常常是主动的。 婊子往往并不愁衣食,甚至有不错的收入。 但她们却可以随时随地把裤子一脱和任何可以给她们带来更大利益的男人上床,拿自己的肉体换取更多的利益, 她们是一群无耻的女人。 婊子和妓女的根本区别在于,妓女只卖肉而不卖心,婊子既卖肉也卖心。 一个女人被迫当上了妓女还有从良的可能性,但一个女人一旦当上了婊子,就彻底没救了。 所以,历史上有的名妓身在青楼心系江山社稷,有的名妓为爱殉情,但你有听说过任何一个婊子有过任何轰轰烈烈的壮举吗? 照我说,婊子不过是一群上得了官场,搅得乱情场的贱货。
但婊子再贱也是人。 虽然她们以卖X为荣,但她们心底里也知道自己有多贱。 被人们在背后指指戳戳的味道也不好受。 夜深人静之时她们也有烦恼。 几千年来,“既要当婊子,又要立牌坊”一直是婊子们的梦。 无奈中国社会越发展,婊子们的地位越低下。 1955年中国开天辟地实行了一夫一妻婚姻制,婊子们更步履维艰。
但是,到了公元21世纪,风水轮回转,婊子们解放了! 她们的梦想终于实现了! 突然间,婊子们成了被社会尊敬、羡慕又惧怕的一群高尚的女人。 谈论自己和人家的男人上床的经历已经成了中国社会婊子族的时髦。 今天的婊子可以堂堂正正地宣称“我爱我的先生,虽然我们没有结婚,但这并不妨碍我为他生一个孩子,孩子是我们爱情的结晶!”(尽管她那位先生法定是别人的) 。 “我爱他,我愿意为他生孩子,这碍着谁了?”成了中国公元2010年的最强音。 什么婚姻法,什么一夫一妻制,什么家庭观念,什么礼仪廉耻,统统成了不入时的垃圾。
京城的婊子一夜之间成了京城名媛。
什么是名媛? 名媛是出身而不是职业。 名媛一词出自于清代李渔的《风筝误•艰配》:“婵娟争觑我,我也觑婵娟,把帝里名媛赶一日批评徧。” 名媛就是上得了厅堂,出得了闺房的名门闺秀。大观园中的黛玉小姐是名媛,闺中的宋庆龄、宋美龄是名媛,袁淑祯、袁静雪是名媛,赵四小姐是名媛,蒋碧薇是名媛,吴健雄是名媛。 红色贵族中,洪晃她妈是名媛,林立果他姐是名媛,毛新宇他姑姑是名媛,李小琳马马虎虎也算半个名媛吧。
那京城的赵小三凭哪一条算是名媛?
名媛会做泼墨那种下三烂的事情的吗?
古时候,一个默默无闻的宫女被皇上临幸了,皇恩便开始浩荡到她的身上。 要是怀上了龙种,从此妾便以子贵,苦尽甜来。 那虽说不尽风流,但也还算是名正言顺,毕竟人家进宫是办了正式手续的。 如今一个三流戏子被一个过气老帅府里的什么人(反正是别人的丈夫)搞了几次,包了几年,弄出个私生子,居然摇身一变,成了京城富甲天下、呼风唤雨、兴风作浪的贵妇了。 今天就连京城的皇家御林军都要甘拜下风,为这贵妇冲锋陷阵,保驾护航。 而一向对花边新闻大开绿灯的中宣部这一次也破例管起了这件事,开始清理网上的传言了。 半个国家都在为这位小三效劳。 这什么狗屁世道! 啥玩意嘛。
以前皇帝的女儿敢这么凶吗? 不敢。 这位小三不就是一个睡人家男人, 拿人家点施舍,靠着人家的权势狐假虎威的高级婊子吗? 幸亏临幸她的不过是过气老帅府上的某人而已。 她要是早生几年,被先帝给看中,又被先帝临幸了,那她还不成了当今国母,三军女帅,我们都要高喊女皇万岁万万岁? 遗憾啊,差来差去就差了个名分,导致她名不正言不顺,以至于她再说她跟她“先生”都“结晶”了,却还是不敢公布她“先生”的尊姓大名。 尽管她身着DIOR的网眼连衣裙,用PIAGET的珠宝腕表衬出自己的风采,还是不能掩饰她的职业:小三,或者说婊子。 不过婊子能做到这个规模,这步田地,也算是出类拔萃了。 所以说她是个“国婊”应该比较贴切。
至于那个国际章,我提都不想提。 如今,在中国连做婊子都不是什么见不得人的事情了,她的那些事情还有什么好谈的。 即使没有这场风波,她也谈不上清纯二字。 她又不是不知道她“姐姐”的底细,可还是自己找上门去,白沾了一身骚。 就算人家是诬陷她,可诈捐那件事是铁板钉钉的吧。 更何况,假如她跟她“姐姐”合伙的生意要是做成了呢? 要是那些传闻千真万确呢? 那我们就对她刮目相看了。 那些事情如果是真,那她就不是国际章,而是国妓章了。 但尽管那样她还算不上是个名妓。 杜十娘、陈圆圆、赛金花、小凤仙会做出诈捐那种丧尽天良的事情吗? 不会的。 所以说,她充其量最多是个国妓。 反正这个国家逼良为娼又不是一天两天的事情了。
但是比起国婊赵,国妓章还是嫩了点。 这场风波后还是跟着姐姐学着点为好。
一个国婊要PK一个国妓,这样的新闻不火爆也难。
肖申克的救赎(觉得写的还不错)
发信人: freeman08 (自由自在), 信区: Wisdom标 题: 肖克莱的救赎观后发信站: BBS 未名空间站 (Tue Feb 23 14:53:31 2010, 美东)
昨天看了,很有意思,写一篇读后感,主要从社会运作的角度看。新开个主题。呵呵。如果是原来年轻时,看后可能主要会是愤怒,现在看了,有时候想笑。几个人物的命运,1.先说那个图书管理员,在监狱里呆了几十年,已经习惯了那样的生活,出来反而不习惯社会,最后只好自杀了。他也想再回到监狱里,回到旧有的习惯了的生活里去。不过可能也厌倦了,没有力量再做一次小案件以便回去,最后选择结束生命,他已经感受不到任何继续存在的价值。依赖于习惯,被惰性抓住,显然是我们人类的通性,当年美国解放黑奴,其实很多奴隶也是不习惯被解放的,因为解放后就要自己选择自己做决定了,没人可以依靠,不习惯。计划经济下出来的人,到市场经济中,要完全自己做主,也是不习惯。差别是有些人能克服习惯,有些人不能,就渴望回到老的习惯生活中去。克服习惯,找到方向,驾驭自己做master而不是slave,并不容易。这一点,可能每个人都有体会。要不为什么少人愿意当老板呢。
2. 下一个就是那个警官,一直都是一个强硬的角色出现的,打人毫不手软。最后被带走的时候,电影对白里说:那家伙哭的象个娘们儿。看国内刚解放剿灭土匪的案子,也有这种情况,当年那个胡传魁的原型,杀人不眨眼的家伙。被抓住的时候,也是瘫软到稀烂。当时的公安人员说,这好像是个通例,很多原来十分残暴的人,倒下的时候都是软的一塌糊涂。残暴和软弱大概都反应他们内心的自我疏离,被莫名的习惯力量所控制,两个极端表现其实都是失控的状态。可以算为病人。
3. 监狱长,精明算计,一切以自我的利益为出发点。某种程度上也追求荣誉和外界的赞扬。内心深处也有隐秘的冲突。其实社会上很多官僚是属于这样的人,在官僚体系运作中,冷酷无情,不惜牺牲别人的生命,来维护自己的“什么东西呢”,钱?地位?但他其实还是在乎社会评价,只不过社会评价价值体系对他来讲是个外在强加的东西。不明所以然。所以事发后,崩溃而自杀。自杀应该是内心冲突的表现。
4.那个黑人,一时冲动犯了罪,其实是有street smart的人。也有人情味,只是没受过教育。他一直基本是保持清醒的,或许是本来就没有太多虚幻的期待。几次假释面谈,很有点幽默,每次他试图顺着审问官的需要去说,总是reject.最后鼓足勇气直抒胸臆,反而approved.我边看边想,面试的时候要注意这个。不能让人觉得你故意在顺着他说。让人疑心你背后到底有什么。哈哈,幽默。
5.普通囚犯。基本上是属于认命的主流。朦胧中过日子,把命运交给别人管理。
6.主角Andy.这个人最有内容,所以放在最后。看完电影,想到一个名词:社会工程师。原来美国的律师就是社会工程师么。他们是理解美国社会(“法律社会”)的关键。打个比方说,就像电脑工程师知道系统哪里有bug一样,他们也知道这个社会是如何设计的,哪里有back door,如何可以建立档案和身份,信息如何流通。他知道那个税务系统、法律系统如何工作,6万块钱怎么才能免税。各种表格如何填写。看来他是深深明了这个社会是如何设计的,说起来律师们是属于立法者的一群,所谓社会的立法者,就相当于电脑的designer。他的水平类似现在的电脑黑客,知道如何钻社会体系的漏洞。(这一点我并非同意他的做法,不过现在能区分合理避税和钻漏洞的差别,合法和非法的差别了)。(实在说,我是计划经济长大,并受影响极深的人,在市场经济下,那个税务如何工作,就应该像学习电脑如何工作一样,要费心“自己学”的,这是最近才认识到。)从电影角色上讲,是立法者被司法者判了刑,又被执法者监管了起来,然后立法者又帮助执法者解决解法律、税务问题最可怜的是执法部门,监狱的狱卒,对法律系统基本茫然,因公配个枪,还要上税。让他干啥就干啥。相当于电脑打字员,电脑如何运作的,一片茫然。每天只要上班打字,或每天上班开车运囚犯就对了。就是这种社会背景下,主角因误判被抓进去了。Andy的最大特点是,有信心,有技术(知道系统如何运作),有智慧:知道这个系统有bug,而且知道必定会有bug。这是他后来能逃出去的基本个人素质要求。有信心,热爱生活和自由,所以他没有放弃。如果放弃了,就没后面的故事了。有技术,这强有力地支持了他的信心,因为技术,他才能在那个环境中通过帮助别人甚至是自己的敌人而有力地改善了自己的环境地位。有智慧,这个很重要。表现在他充分理解这个社会系统的设计是有bug的,这次一个故障把自己给卷进去了,并非完全不可接受。他没有把这个当成纯粹针对个人的事。也就是说He didn't take it personally. 就像一个电脑工程师发现自己设计的软件漏洞误扣了自己的钱一样,他基本是很冷静地接受了这个现实。哭是要哭,就像莎士比亚说的:我们出生时,因为降临到这个由笨蛋们设计的世界里而哭泣。但哭完后他就冷静了:妈的没办法,世界不完美。所以在开始的时候他并没有把那些警官甚至监狱长当成敌人。他充分了解人性弱点和制度的缺陷。了解缺陷,是智慧的起源。否则你碰到缺陷,就会气得要自杀了。我们崩溃是因为自认为不该发生的事情发生了,如果知道事情早晚会发生,当然就不会崩溃了。就像丘吉尔所说:“民主是个不好的制度,但是,还没有发现比它更好的制度,所以我们不得不用它”。实际上,丘吉尔的话,后面隐含了多少人类知识的结晶呢,多少代思想家哲人,日复一日,年复一年的探索,为什么要社会民主,要言论自由,三权分立,社会契约。当丘吉尔说那个话的时候,大概他们比较社会制度就像电脑高手比较操作系统一样,是有所根据和考量的。社会工程师的任务就是,面对现有的零件,你能设计一个什么系统,让大家运作地良好就是了。设计师一定要考虑,可用的零件都是不完美的个体。好了现在主角承认现实。今天我掉到坑里了,怎么生活下去,并想办法出去?
1.首先,在能保持尊严的时候,他一定尽量保持。比如跟那帮恶人打架。再入用自己的知识跟人换点啤酒招待大家。
2. 他骗了所有的人说,自己有个hobby:喜欢刻石头,那帮好心的囚犯还替他找石头呢。直到最后才知道,石头主要还是用来挖洞的吧。此属于处心积虑。之一。不能让人知道的事情就不能让任何人知道,此属于不得已,没办法。切切。
3. 不因系统的失误而惩罚自己,熄灭生命的火焰。所以他持续不停地申请图书馆建设。保持内心的不被玷污以及自身的活力。这个也很好,毕竟要活下去,即使是在监狱里。这还是要点热情的生命力的。这个要学习。
4. 不因自己的失误而惩罚自己,他充分意识到自己在妻子遇害这个事件中的影响,是他的个人当时情感的封闭,把妻子推到了别人那里,但也清醒知道自己不是凶手。所以没有陷入内疚的陷阱。很多人在他那种强烈的挫折下,会陷于内疚而不能自拔,自我惩罚。而他选择了一条正确的路,就是从此做正确的,而不是后悔以前的错误。这需要智慧,勇气,热情。值得学习。
5. 那个年轻人的到来,是个转折点,他先是充满希望地找到监狱长,没想到监狱长是那个反应,愚蠢!愚蠢?到那个年轻人因为可能作为证人而被杀害而自己也被关小黑屋1个月的时候,我产生了一定的绝望心理,不知道如何才能伸冤。设想过我如果在此情况下,能怎么做呢?趁着有外人参观的时候,跑上去伸冤申述?肯定不行,人家把你当成神经病,或者认为这就是普遍情况:谁不觉得自己冤?写信?他申请图书馆的信都是要通过监狱长送出去的。也没门。实际上正常的渠道已经堵死。这之后他又想明白了,妈的没办法,系统不完美,个体不仅仅是不完美,甚至是在执行错误的程序。这是智慧,他又冷静下来了。(设计台词,waichi在旁边说,赶快解脱吧,解脱了就没事了) 好像是从此他才开始挖洞。
6. 逃出去后,财务问题已经不成疑问了,知道他是个财务高手。不过还有个问题,真相怎么散布出去,我还想了不少时间,根据中国的经验,总觉得毫无出路。后来才看明白,毕竟人家是社会工程师,知道社会如何运作。那递给银行职员的包裹,大概都是寄给报社的。这反映了新闻自由是多么重要。没有新闻自由,黑幕更不知道要掩盖多久呢。所以这个电影让我意识到记者是干什么的,无冕之王原来有这个作用。还是好的。社会该有的功能还是有,虽然好多缺陷。你能指望什么呢,狱卒因公配个枪,还不知道自己该不该免税。社会成员都基本是这样的知识水平,能怎样呢?
7. 差点忘了这点,他在那个石头下面放上信和钱,还是很需要信心的。能克服对失望的恐惧而继续怀有希望。这很感人。
8. 结语。主人公是一个有技术,有智慧,热爱生活的人,生活在不完美的社会里而不忘追求自由。值得学习。人是不完美的,社会是有bug的,认识到这个社会是如何设计运作的,在绝望中寻求希望。如是。
--※ 修改:·freeman08 于 Feb 23 17:04:22 2010 修改本文·[FROM: 76.68.]※ 来源:·BBS 未名空间站 海外: mitbbs.com 中国: mitbbs.cn·[FROM: 76.68.]
昨天看了,很有意思,写一篇读后感,主要从社会运作的角度看。新开个主题。呵呵。如果是原来年轻时,看后可能主要会是愤怒,现在看了,有时候想笑。几个人物的命运,1.先说那个图书管理员,在监狱里呆了几十年,已经习惯了那样的生活,出来反而不习惯社会,最后只好自杀了。他也想再回到监狱里,回到旧有的习惯了的生活里去。不过可能也厌倦了,没有力量再做一次小案件以便回去,最后选择结束生命,他已经感受不到任何继续存在的价值。依赖于习惯,被惰性抓住,显然是我们人类的通性,当年美国解放黑奴,其实很多奴隶也是不习惯被解放的,因为解放后就要自己选择自己做决定了,没人可以依靠,不习惯。计划经济下出来的人,到市场经济中,要完全自己做主,也是不习惯。差别是有些人能克服习惯,有些人不能,就渴望回到老的习惯生活中去。克服习惯,找到方向,驾驭自己做master而不是slave,并不容易。这一点,可能每个人都有体会。要不为什么少人愿意当老板呢。
2. 下一个就是那个警官,一直都是一个强硬的角色出现的,打人毫不手软。最后被带走的时候,电影对白里说:那家伙哭的象个娘们儿。看国内刚解放剿灭土匪的案子,也有这种情况,当年那个胡传魁的原型,杀人不眨眼的家伙。被抓住的时候,也是瘫软到稀烂。当时的公安人员说,这好像是个通例,很多原来十分残暴的人,倒下的时候都是软的一塌糊涂。残暴和软弱大概都反应他们内心的自我疏离,被莫名的习惯力量所控制,两个极端表现其实都是失控的状态。可以算为病人。
3. 监狱长,精明算计,一切以自我的利益为出发点。某种程度上也追求荣誉和外界的赞扬。内心深处也有隐秘的冲突。其实社会上很多官僚是属于这样的人,在官僚体系运作中,冷酷无情,不惜牺牲别人的生命,来维护自己的“什么东西呢”,钱?地位?但他其实还是在乎社会评价,只不过社会评价价值体系对他来讲是个外在强加的东西。不明所以然。所以事发后,崩溃而自杀。自杀应该是内心冲突的表现。
4.那个黑人,一时冲动犯了罪,其实是有street smart的人。也有人情味,只是没受过教育。他一直基本是保持清醒的,或许是本来就没有太多虚幻的期待。几次假释面谈,很有点幽默,每次他试图顺着审问官的需要去说,总是reject.最后鼓足勇气直抒胸臆,反而approved.我边看边想,面试的时候要注意这个。不能让人觉得你故意在顺着他说。让人疑心你背后到底有什么。哈哈,幽默。
5.普通囚犯。基本上是属于认命的主流。朦胧中过日子,把命运交给别人管理。
6.主角Andy.这个人最有内容,所以放在最后。看完电影,想到一个名词:社会工程师。原来美国的律师就是社会工程师么。他们是理解美国社会(“法律社会”)的关键。打个比方说,就像电脑工程师知道系统哪里有bug一样,他们也知道这个社会是如何设计的,哪里有back door,如何可以建立档案和身份,信息如何流通。他知道那个税务系统、法律系统如何工作,6万块钱怎么才能免税。各种表格如何填写。看来他是深深明了这个社会是如何设计的,说起来律师们是属于立法者的一群,所谓社会的立法者,就相当于电脑的designer。他的水平类似现在的电脑黑客,知道如何钻社会体系的漏洞。(这一点我并非同意他的做法,不过现在能区分合理避税和钻漏洞的差别,合法和非法的差别了)。(实在说,我是计划经济长大,并受影响极深的人,在市场经济下,那个税务如何工作,就应该像学习电脑如何工作一样,要费心“自己学”的,这是最近才认识到。)从电影角色上讲,是立法者被司法者判了刑,又被执法者监管了起来,然后立法者又帮助执法者解决解法律、税务问题最可怜的是执法部门,监狱的狱卒,对法律系统基本茫然,因公配个枪,还要上税。让他干啥就干啥。相当于电脑打字员,电脑如何运作的,一片茫然。每天只要上班打字,或每天上班开车运囚犯就对了。就是这种社会背景下,主角因误判被抓进去了。Andy的最大特点是,有信心,有技术(知道系统如何运作),有智慧:知道这个系统有bug,而且知道必定会有bug。这是他后来能逃出去的基本个人素质要求。有信心,热爱生活和自由,所以他没有放弃。如果放弃了,就没后面的故事了。有技术,这强有力地支持了他的信心,因为技术,他才能在那个环境中通过帮助别人甚至是自己的敌人而有力地改善了自己的环境地位。有智慧,这个很重要。表现在他充分理解这个社会系统的设计是有bug的,这次一个故障把自己给卷进去了,并非完全不可接受。他没有把这个当成纯粹针对个人的事。也就是说He didn't take it personally. 就像一个电脑工程师发现自己设计的软件漏洞误扣了自己的钱一样,他基本是很冷静地接受了这个现实。哭是要哭,就像莎士比亚说的:我们出生时,因为降临到这个由笨蛋们设计的世界里而哭泣。但哭完后他就冷静了:妈的没办法,世界不完美。所以在开始的时候他并没有把那些警官甚至监狱长当成敌人。他充分了解人性弱点和制度的缺陷。了解缺陷,是智慧的起源。否则你碰到缺陷,就会气得要自杀了。我们崩溃是因为自认为不该发生的事情发生了,如果知道事情早晚会发生,当然就不会崩溃了。就像丘吉尔所说:“民主是个不好的制度,但是,还没有发现比它更好的制度,所以我们不得不用它”。实际上,丘吉尔的话,后面隐含了多少人类知识的结晶呢,多少代思想家哲人,日复一日,年复一年的探索,为什么要社会民主,要言论自由,三权分立,社会契约。当丘吉尔说那个话的时候,大概他们比较社会制度就像电脑高手比较操作系统一样,是有所根据和考量的。社会工程师的任务就是,面对现有的零件,你能设计一个什么系统,让大家运作地良好就是了。设计师一定要考虑,可用的零件都是不完美的个体。好了现在主角承认现实。今天我掉到坑里了,怎么生活下去,并想办法出去?
1.首先,在能保持尊严的时候,他一定尽量保持。比如跟那帮恶人打架。再入用自己的知识跟人换点啤酒招待大家。
2. 他骗了所有的人说,自己有个hobby:喜欢刻石头,那帮好心的囚犯还替他找石头呢。直到最后才知道,石头主要还是用来挖洞的吧。此属于处心积虑。之一。不能让人知道的事情就不能让任何人知道,此属于不得已,没办法。切切。
3. 不因系统的失误而惩罚自己,熄灭生命的火焰。所以他持续不停地申请图书馆建设。保持内心的不被玷污以及自身的活力。这个也很好,毕竟要活下去,即使是在监狱里。这还是要点热情的生命力的。这个要学习。
4. 不因自己的失误而惩罚自己,他充分意识到自己在妻子遇害这个事件中的影响,是他的个人当时情感的封闭,把妻子推到了别人那里,但也清醒知道自己不是凶手。所以没有陷入内疚的陷阱。很多人在他那种强烈的挫折下,会陷于内疚而不能自拔,自我惩罚。而他选择了一条正确的路,就是从此做正确的,而不是后悔以前的错误。这需要智慧,勇气,热情。值得学习。
5. 那个年轻人的到来,是个转折点,他先是充满希望地找到监狱长,没想到监狱长是那个反应,愚蠢!愚蠢?到那个年轻人因为可能作为证人而被杀害而自己也被关小黑屋1个月的时候,我产生了一定的绝望心理,不知道如何才能伸冤。设想过我如果在此情况下,能怎么做呢?趁着有外人参观的时候,跑上去伸冤申述?肯定不行,人家把你当成神经病,或者认为这就是普遍情况:谁不觉得自己冤?写信?他申请图书馆的信都是要通过监狱长送出去的。也没门。实际上正常的渠道已经堵死。这之后他又想明白了,妈的没办法,系统不完美,个体不仅仅是不完美,甚至是在执行错误的程序。这是智慧,他又冷静下来了。(设计台词,waichi在旁边说,赶快解脱吧,解脱了就没事了) 好像是从此他才开始挖洞。
6. 逃出去后,财务问题已经不成疑问了,知道他是个财务高手。不过还有个问题,真相怎么散布出去,我还想了不少时间,根据中国的经验,总觉得毫无出路。后来才看明白,毕竟人家是社会工程师,知道社会如何运作。那递给银行职员的包裹,大概都是寄给报社的。这反映了新闻自由是多么重要。没有新闻自由,黑幕更不知道要掩盖多久呢。所以这个电影让我意识到记者是干什么的,无冕之王原来有这个作用。还是好的。社会该有的功能还是有,虽然好多缺陷。你能指望什么呢,狱卒因公配个枪,还不知道自己该不该免税。社会成员都基本是这样的知识水平,能怎样呢?
7. 差点忘了这点,他在那个石头下面放上信和钱,还是很需要信心的。能克服对失望的恐惧而继续怀有希望。这很感人。
8. 结语。主人公是一个有技术,有智慧,热爱生活的人,生活在不完美的社会里而不忘追求自由。值得学习。人是不完美的,社会是有bug的,认识到这个社会是如何设计运作的,在绝望中寻求希望。如是。
--※ 修改:·freeman08 于 Feb 23 17:04:22 2010 修改本文·[FROM: 76.68.]※ 来源:·BBS 未名空间站 海外: mitbbs.com 中国: mitbbs.cn·[FROM: 76.68.]
Tuesday, February 16, 2010
Develop Web Services with Axis2 - System Setup
Axis2 is a very cool application platform for web service development. I'm doing a small project about how to develop a distributed raytracing web service based on Axis2. The advantages of Axis2 is obvious: Speed, Flexibility, Stability, Component-oriented Deployment, Transport Framework, and WSDL Support. But it has disadvantage; it is difficult to set up and implement.
Before we start, there are some basic concepts that you need to know.
1. Web service
In a web service, two kinds of entities are involved: the server and the client. They communicate with each other by some predefined protocol, e.g. http. The server provides some APIs for the clients, and the client then make use of these APIs to do its own job.
2. SOAP (Simple Object Access Protocol)
SOAP is a XML-based procotol specification used for exchanging messages between different applications (from different machines). SOAP is usually based on http, or other application layer protocols. It's the foundation layer of web service stack.
3. WSDL (Web Service Description Language)
WSDL is a XML-based language for describing web serivces. The WSDL defines services as collections of network endpoints, or ports. A port is defined by associating a network address with a reusable binding, and a collection of ports defines a service. Messages are abstract descriptions of the data being exchanged, and port types are abstract collections of supported operations.
Now it's time to start! To have an overall understanding of Axis2, please refer to official Apache Axis2 website here. The following content will tell you how to set up your Axis2 environment. I'm using intel machine with Win Vista system.
1. Install neccessary software
Install Apache Tomcat server. I'm using Tomcat6, but 5.5 would also be fine. You can find it here. Make sure you have correctly installed your JAVA JDK. Then you need to download Axis2 from Apache official website. I used Axis2 1.5 here. Also, you need to install Apache Ant.
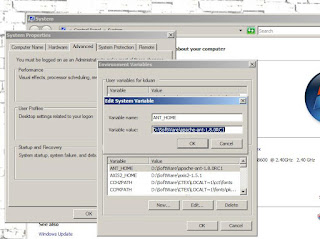
2. Set up environment variables
After installation, you need to set up ANT_HOME environment variable in your system settings. The value of this variable should be the installation path of ant on your machine. Then edit the "path" variable, add ";%ANT_HOME%\bin" to the end. Do this for your JAVA JRE and Axis2. The corresponding environment variables should be JAVA_HOME and AXIS2_HOME.
3. Deploy your Axis2 service
After you have installed your Axis2. Go to "webapp" folder under your Axis2 directory; you can see a build.xml file, and then switch into this path in your DOS console. Since you have already set up the environment variable for ANT, you just run the command "ant" under this folder. This will launch "ant build" with the build.xml file. After build successfully, you can find a new f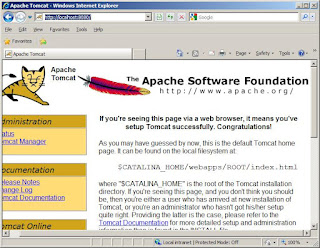 older "dist" under Axis2 directory, which contains a axis2.war file. Now copy this file into the "webapps" folder under your Tomcat directory. (Re)start Tomcat by running startup.bat under the "bin" folder. This will automatically deploy your Axis2 service. If this is done successfully, you would be able to see a new Axis2 folder within the "webapps" folder. In addition, you can open your explorer and go to http://localhost:8080/ (8080 is the default port number of Tomcat, you can always alter it in the configuration file). If this page is successfully loaded, your Tomcat is installed correctly. Then goto http://localhost:8080/axis2 which is the admin page of your Axis2 services. You can view your current services, change access information, ect.
older "dist" under Axis2 directory, which contains a axis2.war file. Now copy this file into the "webapps" folder under your Tomcat directory. (Re)start Tomcat by running startup.bat under the "bin" folder. This will automatically deploy your Axis2 service. If this is done successfully, you would be able to see a new Axis2 folder within the "webapps" folder. In addition, you can open your explorer and go to http://localhost:8080/ (8080 is the default port number of Tomcat, you can always alter it in the configuration file). If this page is successfully loaded, your Tomcat is installed correctly. Then goto http://localhost:8080/axis2 which is the admin page of your Axis2 services. You can view your current services, change access information, ect.
OK! You have done really well! BUT remember this is just a beginning. There would be a lot of work to do later. Take a breath and we'll come back soon!
Before we start, there are some basic concepts that you need to know.
1. Web service
In a web service, two kinds of entities are involved: the server and the client. They communicate with each other by some predefined protocol, e.g. http. The server provides some APIs for the clients, and the client then make use of these APIs to do its own job.
2. SOAP (Simple Object Access Protocol)
SOAP is a XML-based procotol specification used for exchanging messages between different applications (from different machines). SOAP is usually based on http, or other application layer protocols. It's the foundation layer of web service stack.
3. WSDL (Web Service Description Language)
WSDL is a XML-based language for describing web serivces. The WSDL defines services as collections of network endpoints, or ports. A port is defined by associating a network address with a reusable binding, and a collection of ports defines a service. Messages are abstract descriptions of the data being exchanged, and port types are abstract collections of supported operations.
Now it's time to start! To have an overall understanding of Axis2, please refer to official Apache Axis2 website here. The following content will tell you how to set up your Axis2 environment. I'm using intel machine with Win Vista system.
1. Install neccessary software
Install Apache Tomcat server. I'm using Tomcat6, but 5.5 would also be fine. You can find it here. Make sure you have correctly installed your JAVA JDK. Then you need to download Axis2 from Apache official website. I used Axis2 1.5 here. Also, you need to install Apache Ant.

2. Set up environment variables
After installation, you need to set up ANT_HOME environment variable in your system settings. The value of this variable should be the installation path of ant on your machine. Then edit the "path" variable, add ";%ANT_HOME%\bin" to the end. Do this for your JAVA JRE and Axis2. The corresponding environment variables should be JAVA_HOME and AXIS2_HOME.
3. Deploy your Axis2 service
After you have installed your Axis2. Go to "webapp" folder under your Axis2 directory; you can see a build.xml file, and then switch into this path in your DOS console. Since you have already set up the environment variable for ANT, you just run the command "ant" under this folder. This will launch "ant build" with the build.xml file. After build successfully, you can find a new f
 older "dist" under Axis2 directory, which contains a axis2.war file. Now copy this file into the "webapps" folder under your Tomcat directory. (Re)start Tomcat by running startup.bat under the "bin" folder. This will automatically deploy your Axis2 service. If this is done successfully, you would be able to see a new Axis2 folder within the "webapps" folder. In addition, you can open your explorer and go to http://localhost:8080/ (8080 is the default port number of Tomcat, you can always alter it in the configuration file). If this page is successfully loaded, your Tomcat is installed correctly. Then goto http://localhost:8080/axis2 which is the admin page of your Axis2 services. You can view your current services, change access information, ect.
older "dist" under Axis2 directory, which contains a axis2.war file. Now copy this file into the "webapps" folder under your Tomcat directory. (Re)start Tomcat by running startup.bat under the "bin" folder. This will automatically deploy your Axis2 service. If this is done successfully, you would be able to see a new Axis2 folder within the "webapps" folder. In addition, you can open your explorer and go to http://localhost:8080/ (8080 is the default port number of Tomcat, you can always alter it in the configuration file). If this page is successfully loaded, your Tomcat is installed correctly. Then goto http://localhost:8080/axis2 which is the admin page of your Axis2 services. You can view your current services, change access information, ect.OK! You have done really well! BUT remember this is just a beginning. There would be a lot of work to do later. Take a breath and we'll come back soon!
Subscribe to:
Comments (Atom)